Databases vs. data warehouses vs. data lakes
Understand how databases, data warehouses, and data lakes manage data differently. Discover their applications in various industries and the benefits they offer.

Data is everywhere, but not all data is stored—or used—the same way. Businesses dealing with high-speed transactions need a system that can instantly process data. Analysts looking for trends over time need a structure that supports complex queries. Companies working with massive, unstructured datasets—everything from images to raw logs—need storage that scales without rigid organization.
That’s where databases, data warehouses, and data lakes come in. While they all store data, each system serves different purposes. Understanding the nuances between these systems is key to choosing the right one for your business needs.
What is a database?
A database is a collection of data stored and accessed electronically. It is designed to manage, retrieve, and update data efficiently. Databases store data in various ways, including rows and columns, pairs of values, or graphs.
Key features of databases include:
Stored data: Data stored in ways that make it easy for applications to find and process reliably
Online transaction processing (OLTP): Optimized for handling a large number of short online transactions, such as inserting, updating, or deleting records
Data management: Support operations such as indexing, querying, and managing user access
Databases are widely used in applications that require rapid transactional updates, such as customer relationship management (CRM) systems, financial systems, and online retail platforms.
What is a data warehouse?
A data warehouse is a centralized repository that stores large volumes of structured data for analysis and reporting. Unlike databases, data warehouses focus on data integration from multiple sources, making complex queries and data analysis easier.
Data warehouses support online analytical processing (OLAP), which involves complex queries to reveal insights and trends over time. This makes them helpful for business intelligence and decision-making processes that need historical data analysis.
Features of data warehouses include:
Structured data: Organized in a consistent manner, often using a Star or Snowflake schema
Data analytics: Optimized for handling complex queries and aggregations, making it suitable for data science and business intelligence applications
Historical data storage: Historical data supports trend analysis and reporting over time.
Data warehouses are helpful for organizations that need to analyze large datasets across multiple departments, such as sales, marketing, and finance, to make informed business decisions.
What is a data lake?
A data lake holds large amounts of raw data in its native format. Unlike data warehouses, data lakes accommodate structured and unstructured data, including text, images, and videos.
Features of data lakes include:
Flexibility: Support for a wide variety of data types without the need for predefined database schemas
Data integration: Centralized storage for data from multiple sources, facilitating data processing and advanced analytics
Scalability: Increases storage and processing capabilities as data grows
Data lakes are particularly useful for organizations that need a centralized repository for diverse datasets, such as those involved in research, big data analytics, or machine learning projects. They help data scientists and analysts access and process data without constraints imposed by structured storage systems.
Comparison of features
Selecting between a database, data warehouse, or data lake depends on specific business needs and data characteristics. Databases are suitable for applications requiring quick data retrieval and updates. Data warehouses are best for businesses focusing on data-driven decision-making through historical analysis. Data lakes cater to those aiming for flexibility and insight in data science and analytics.
| Data structure | Purpose | Performance | User base | Data processing | Scalability | |
|---|---|---|---|---|---|---|
| Database |
Can be structured or semi-structured | Transaction processing | Optimized for fast transaction processing | IT professionals managing transactional data | OLTP | Can be limited by hardware for large-scale data |
| Data warehouse | Structured with pre-defined schemas | Analytics and reporting | Optimized for complex query performance | Business analysts and decision-makers | OLAP | Scalable but with complex data transformation processes |
| Data lake | Supports all data types, including unstructured | Data integration and exploration | Performance can vary, as data is not structured, and insight is more critical than speed | Data scientists and researchers | Batch processing and real-time analytics | Highly scalable with cloud-based storage |
Use cases
Now that we know the differences between the three types, what are they good for?
Database use cases
Databases serve several functions across multiple industries. They are primarily used for OLTP, where rapid and consistent transaction handling is a priority. For example, in retail, databases efficiently manage inventory, sales, and customer data. In healthcare, they store patient records and manage appointment scheduling, keeping data both accurate and readily accessible. Finally, financial institutions use databases for real-time transaction processing, fraud detection, and customer relationship management.
Data warehouse use cases
Since data warehouses are optimized for data analytics and reporting, they are the backbone of business intelligence tools that provide historical data insights. Retail businesses use data warehouses to analyze sales trends, customer behavior, and inventory management over time. In the healthcare industry, data warehouses consolidate patient data from multiple sources for comprehensive analyses such as treatment outcomes and operational efficiency. Financial sectors use data warehouses for risk assessment, customer profitability analyses, and compliance reporting.
Data lake use cases
Data lakes are designed for big data processing tasks and storing large amounts of raw data. Organizations use them for advanced data science tasks. For instance, media companies use data lakes to store video, audio, and social media content, which they analyze for trends and viewer preferences. Data lakes support genomic research in healthcare by storing large, unstructured datasets needed for personalized medicine. Financial services use data lakes for fraud detection by integrating transaction logs, social media feeds, and customer interactions.
These examples illustrate the different applications of databases, data warehouses, and data lakes across industries, each serving separate roles in data management.
Aerospike databases, data lakes, data warehouse
Aerospike is an operational database built for high-speed distributed ACID transactions and real-time analytics. It handles structured OLTP workloads with low latency, making it a reliable choice for use cases and industry verticals that require efficient, strongly consistent data processing. While Aerospike doesn’t call for a strict schema, stored data is typically structured, including point-in-time records, including data such as a customer’s current account balance, ongoing prescriptions, or recent transactions.
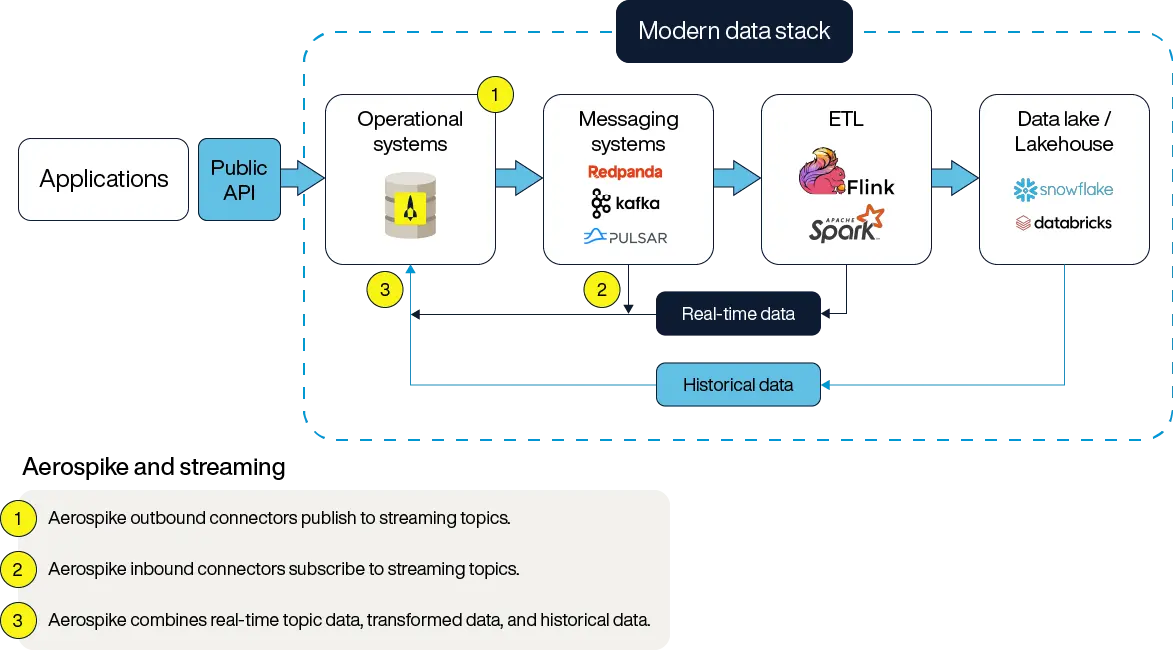
Aside from being an operational database, Aerospike integrates with data warehouses, where historical snapshots of transactional data are often aggregated for analysis. Unlike an OLTP system, such as a data lake, that captures data in its present state, data warehouses track changes over time. This capability is a pivotal win for those looking to make business intelligence decisions. Think of it this way: the relationship is similar to how a single image (OLTP data) can be transformed into a time-lapse video (historical data inside a data warehouse), revealing patterns and trends over time.
Aerospike seamlessly moves data into data warehouses via outbound connectors like Kafka. This integration allows organizations to make real-time decisions while preserving historical insights, ensuring they can act on both immediate operational needs and long-term business trends.
By bridging real-time OLTP systems with historical analysis in data warehouses, Aerospike provides a scalable, high-performance solution that supports modern data infrastructure.