Introduction to fuzzy matching
Dive into fuzzy matching techniques that enhance data management. Explore algorithms, benefits, and tips for implementation in real-time applications.

Fuzzy matching, also known as approximate string matching, identifies strings that are similar but not identical. It is particularly useful when data may be inconsistent or contain errors, such as typographical mistakes or varying spellings. Fuzzy matching algorithms increase the flexibility of a match between strings by considering factors such as character similarity and sequence alignment. Furthermore, fuzzy matching streamlines operations by eliminating redundant data entries, helping maintain a clean and efficient database. The flexibility of fuzzy matching algorithms enables businesses to adapt to various data formats and structures without extensive customization. This adaptability minimizes the need for manual intervention, saving time, and reducing operational costs.
For example, in a customer database, an entry might read “John Doe” while another records the same individual as “Jon Doe.” Traditional matching methods would treat these as two distinct entries. However, fuzzy matching techniques can recognize these approximate matches despite the different spelling. By leveraging a similarity threshold, fuzzy matching determines how closely two strings align, making it invaluable for resolving such minor variations in data.
Fuzzy logic makes these algorithms work, providing a framework to accommodate these uncertainties. By applying fuzzy matching in contexts such as data cleansing, search and retrieval, and record linkage, data systems can be more accurate and reliable. This approach is important in fields such as healthcare and finance, where data integrity is paramount.
Algorithms and technical explanation
Fuzzy matching algorithms identify similarities between strings, even when they are not identical. It does this through several different techniques.
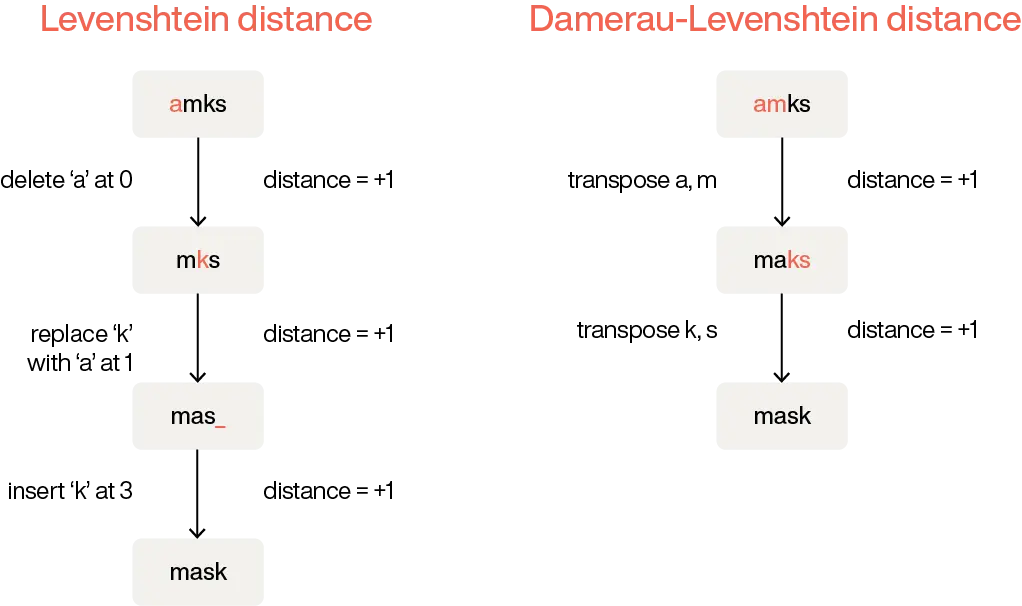
Levenshtein distance algorithm
The Levenshtein distance algorithm calculates the number of single-character edits needed to transform one string into another, making it useful in various applications, including spell checkers and DNA sequencing. The Damerau-Levenshtein variant extends this by including transpositions, which are common in typing errors.
Hamming distance algorithm
While similar, this Hamming distance algorithm works only on strings of equal length and counts differing positions, making it useful for error detection in data transmission. On the other hand, the n-gram approach breaks strings into smaller chunks, or n-grams, and compares these to detect partial matches, commonly used in search engines and text analytics.
The Bitap algorithm
Often used in full-text search engines, the Bitap algorithm uses bitwise operations to perform approximate string matching, which makes it more efficient when handling large texts. Dynamic programming, a method often used with these algorithms, systematically solves complex problems by breaking them down into simpler subproblems and optimizing the matching process.
Understanding the workings of these algorithms is crucial for implementing effective fuzzy matching systems. They differ in terms of complexity, accuracy, and computational cost. Levenshtein and its variants are computationally intensive but offer high accuracy. N-gram and Bitap balance speed and accuracy, making them suitable for real-time applications. Each algorithm has its strengths; picking one is based on the specific requirements of the task at hand, such as the size of the dataset, the nature of the text, and the acceptable error rate.
Fuzzy algorithm | Use case | Benefits | Disadvantages |
|---|---|---|---|
Levenshtein and its variants | Spell checkers and DNA sequencing | High accuracy | Computationally intensive |
N-gram | Search engines and text analytics | Higher speed, especially for partial matches | Lower accuracy |
Bitap | Real-time applications | Higher speed, especially when handling large texts | Lower accuracy |
Dynamic programming, a method often used with these algorithms, systematically solves complex problems by breaking them into simpler subproblems and optimizing the matching process. Other notable fuzzy matching algorithms include fuzzy string matching approaches and fuzzy search techniques. For instance, the cosine similarity method calculates similarity by measuring angles between vectors, while phonetic algorithms help identify names or words that sound similar but differ in spelling.
Find out how vectors handle fuzzy lookups for better search results.
Additionally, deterministic matching ensures exact matches without ambiguity, while fuzzy matching algorithms provide flexibility in accommodating variations. Each matching algorithm has strengths and weaknesses, which must be carefully chosen based on dataset size and use case requirements.
Applications and use cases
Fuzzy matching can be used to link patient records in healthcare. This process accurately matches records from different healthcare providers even if spelling and formatting aren’t identical. By maintaining comprehensive health records, it reduces the likelihood of medical errors and improves patient care.
Fuzzy matching is used in fraud detection in the finance sector. By identifying suspicious activities through pattern recognition, financial institutions mitigate risks and protect consumers from fraudulent transactions. In the insurance industry, fuzzy matching reduces claim deduplication, so duplicate claims are identified and processed efficiently, reducing costs and improving service delivery.
Auto-suggest features on e-commerce platforms and search engines heavily rely on fuzzy matching. These systems enhance the user experience by providing suggestions based on approximate string matches despite typographical errors or alternative spellings. Linking records in large databases, such as government databases or customer relationship management systems, is another area where fuzzy matching integrates and manages different data sources.
Spam filtering systems also use fuzzy matching algorithms to identify and filter out unwanted email content. By analyzing the likelihood of a message being spam based on its content and structure, these systems help prevent unwanted email messages.
Fuzzy matching's versatility across sectors shows its importance in addressing data-related challenges, from helping systems work better to making users happier.
Challenges and limitations
Fuzzy matching, while powerful, is no panacea. It faces issues in accuracy and efficiency, especially with large datasets or complex matching criteria. Computational algorithms like Levenshtein distance and Hamming distance take up system resources and can affect them.
Additionally, fuzzy matching can result in false positives, where non-matching data is incorrectly identified as a match. This can complicate results, particularly in critical applications such as healthcare and finance.
Another limitation is the subjective nature of "closeness" in matching. What constitutes a match can vary depending on the context, leading to potential inconsistencies or misinterpretations. The balance between sensitivity (catching all potential matches) and specificity (ensuring matches are accurate) is delicate and may require iterative tuning and customization based on your application.
Furthermore, different programming languages and platforms might not implement fuzzy matching similarly, so it’s important to understand both the algorithms and the data structure involved. Tools like FuzzyWuzzy in Python or Java, Java’s Apache Commons Test, Intuit Fuzzy Matcher, Simmetrics, and SecondString libraries make it easier but still require careful configuration and testing to meet specific needs. Excel users can use add-ons or scripts to incorporate fuzzy matching in spreadsheets.
How well fuzzy matching works also depends on the quality of the data. Poorly structured or inconsistent data can make matching errors more likely and require more data preprocessing and validation steps. Maintaining the relevance and accuracy of fuzzy matching algorithms can be an ongoing challenge in dynamic environments where data changes frequently.
Despite these limitations, fuzzy matching is indispensable for tasks like data deduplication and record linkage. However, it’s important to acknowledge and address its limitations.
Discover how vector databases enable advanced fuzzy matching for better query results in our Making sense of vectors blog.
Implementation and error reduction
So, how do you do fuzzy matching? It involves selecting an appropriate algorithm and integrating it into your existing systems.
To reduce errors such as false positives, look at tuning algorithm parameters. Adjust threshold values to balance sensitivity and specificity to ensure matches are neither too strict nor too lenient. Pre-process data by standardizing formats, removing duplicates, and cleansing inconsistencies to make matches more accurate. Here are some specific examples for each technique.
Levenshtein distance algorithm examples
Key parameters to tune:
Distance threshold: Define the maximum edit distance allowable for two strings to be considered a match. For example:
A distance threshold of 1 means only one edit (insertion, deletion, or substitution) is allowed, so "color" and "colour" would match because there is only one insertion (the "u").
A distance threshold of 2 would allow matches with two edits, such as "color" and "collar" (one substitution and one insertion).
Weighted edits: Assign different penalties to substitutions, insertions, or deletions based on context. For instance:
Substitutions might be penalized more heavily when matching scientific names or codes.
Implementation tips:
For short strings such as names, lower thresholds work best to reduce false positives.
For longer strings such as product descriptions, higher thresholds accommodate more variations.
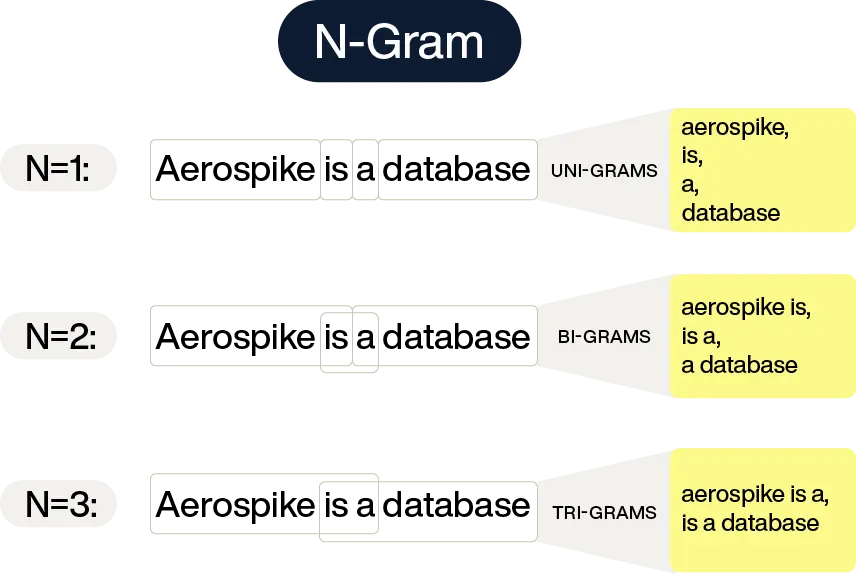
N-gram similarity algorithm examples
Key parameters to tune:
N-gram size: Define the size of the substrings (N-grams) used for comparison.
For example:A size of 2 (bigrams) means breaking the string into overlapping two-character segments.
Example: "color" → {"co", "ol", "lo", "or"}.
A size of 3 (trigrams) means breaking the string into overlapping three-character segments, which is a stricter standard.
Example: "color" → {"col", "olo", "lor"}.
Examples:
With bigram size, "color" and "colour" would match moderately, as the overlapping bigrams are {"co", "ol", "lo", "or"} vs. {"co", "ol", "lo", "ou", "ur"} → 3/5 overlap.
With trigram size, "color" and "colour" have less overlap, as trigrams offer a stricter comparison.
Similarity threshold: Define the minimum overlap required between N-grams for two strings to be considered a match. For example, a similarity threshold of 0.6 means that at least 60% of the N-grams must overlap.
Example: "color" and "colour" (bigram overlap = 3/5 = 0.6) would just match at this threshold.
Increasing the threshold reduces false positives but might exclude near matches.
Weighted N-grams: Assign varying importance to specific N-grams based on context. For example:
In email addresses, bigrams from the domain (e.g., "Gmail") might be weighted higher than the username.
In product names, prefixes or certain substrings could be prioritized to emphasize brand consistency.
Bitap algorithm examples
Key parameters to tune:
Error threshold: Define the maximum number of allowable errors (insertions, deletions, or substitutions) for a match. For example:
An error threshold of 1 allows one typo, so "Samsung Galaxy" would match "Samzung Galaxy."
An error threshold of 2 accommodates more variations, such as "Samsng Galaxi," but increases the likelihood of false positives.
Pattern length: The algorithm’s performance depends on the length of the pattern being searched. Longer patterns require more computational resources, so breaking them up might work better.
For instance, break "Samsung Galaxy Ultra" into smaller substrings such as "Samsung Galaxy" and "Ultra" to improve accuracy and speed.
Implementation tips:
To improve matching accuracy, normalize data by converting text to lowercase, removing special characters, and standardizing formats (e.g., "128 GB" to "128 gb").
Use lower error thresholds for applications where precision is important, such as name matching.
Preprocess data to standardize formats, remove duplicates, and handle missing values.
For example, normalize "St." and "Street" to the same format in address matching.
Testing and validation are important. Implement unit tests to verify how the algorithm performs across different datasets. Analyze false positives and negatives to refine the matching criteria. Adjust thresholds iteratively to improve precision and recall, tailoring it to the specific needs of your data. This is especially true for large datasets with diverse query patterns. Implement unit tests to simulate edge cases such as typos or partial strings, and regularly review mismatched results to refine algorithm parameters.
Document the implementation process. Clear documentation helps in maintenance and future updates. Include the chosen algorithms, parameter settings, and any customizations made to the matching process.
Lastly, stay updated with the latest advancements. Fuzzy matching techniques evolve, and incorporating new methods can lead to more efficient and accurate results.
Next steps
While fuzzy matching identifies approximate string matches, vector search takes it a step further by enabling semantic searches that go beyond textual similarity. Aerospike's Vector Search capabilities, now integrated with tools such as LangChain, let developers combine these approaches for robust database queries. With vector embeddings, Aerospike identifies conceptually similar data while retaining the benefits of fuzzy matching for string-based errors. This hybrid approach means businesses get more accurate, high-performance queries, whether resolving data inconsistencies, powering AI-driven recommendations, or enhancing user searches. With Aerospike’s low-latency architecture, developers can deliver these advanced search functionalities at scale—making it the ideal solution for today’s data-intensive applications.



