How we did it: Enhancing our search engine with AI and vectors
We built a cutting-edge hybrid search engine combining vector and keyword search for enhanced relevance and performance.

At the beginning of the summer, I, along with my fellow intern Vaibhav and manager Art, embarked on a journey to update the aerospike.com search engine. This blog will take you through our experience and the fundamentals of how we built a better search.
Aerospike’s previous search engine utilized basic keyword search. The limit of keyword search, however, is that it matches only exact terms, missing context or intent behind the query. Vector databases enable semantic search, capturing the deeper meaning in queries to deliver more relevant and accurate results. We decided to implement a more sophisticated hybrid search system utilizing Aerospike’s very own vector database and vector search features. In the end, we created a search engine that combines the capabilities of both full-text and semantic search to return more relevant and usable search results for users exploring the site while demonstrating Aerospike’s technology in a meaningful way.
Here are the key parts of the project, which I’ll detail:
Chunking data and scraping the relevant sites
Creating a vector index
Building an inverted index for keywords
Combining keyword and vector search
Re-ranking results with fused algorithms
Designing a user-friendly search interface
Future plans
Chunking and loading the data
Our first big task was to figure out how to segment, or chunk, the documents into logical sections and load this data into the Aerospike Database. Luckily, we had guidance from previous demos made by those much smarter and more experienced (a.k.a. Art’s very cool RAG demo), which used Scrapy to scrape the Aerospike documentation sites.
The quality of the search relied on getting good data, so one challenge we faced was ensuring that we scraped only the useful parts of the documentation sites: the title, description, and content. To address this, we created detailed XPath queries to extract the right parts of the site, excluding the miscellaneous links and related (but irrelevant) articles that might skew our search results.
Building the vector index
To create an index for our search engine, we first determined what data would be necessary to store in order to get accurate and relevant results: essential metadata and processed content for each document chunk. In our vector database, we stored each chunk’s title, URL, description, content, and index number. We used LlamaIndex to split each document into smaller chunks, and Google Cloud’s Vertex AI to generate the vector embeddings on the title, description, and content of each chunk. Additionally, we stored tokenized and filtered versions of the title, description, and embedding for the full-text search. To normalize the text, we used a natural language processing library called spaCy to tokenize, lemmatize, lowercase, and remove common stop words (e.g. “what” and “where”).
Building the inverted index
When we started testing and evaluating the results of our keyword search, we learned that the most efficient method to retrieve keyword data was with an inverted index. Like a glossary at the end of a textbook, an inverted index maps each keyword to its occurrences across a set of documents.

We utilized a word-level inverted index to capture the locations of every keyword in the scraped Aerospike documents. For each unique keyword, the index logged every chunk where it appeared, identified by its chunk ID (a combination of the URL and chunk number), as well as the keyword’s frequency and position within that corresponding chunk–useful data for ranking the results based on relevance later on. Instead of scanning every document for a specific keyword during a search, we could now use the inverted index to find all the chunks where the keyword was present, speeding up the retrieval process significantly.
Implementing vector search
Aerospike made semantic search simple (and so fast!). To implement vector-based search, we first embedded (or vectorized) the user’s query. This converted the query into vectors to capture its semantic meaning. Once embedded, we used Aerospike Vector Search to format the results.
As we experimented, we learned we could further improve speed by caching the results of common queries. We also created a least recently used (LRU) cache to store query embeddings. Now, common queries wouldn’t need to be re-embedded, improving the efficiency of semantic search as a whole.
Implementing keyword search
While vector search excels at finding semantically similar results, it can sometimes overlook exact matches or specific keywords that users expect to find in their results. To address this, we implemented a complementary keyword search.
We first processed the user’s query, using spaCy to lemmatize and remove stop words and turn the query into a list of normalized keyword tokens. We then performed a batch read on all of the keywords in the filtered query to retrieve every document where any keyword was present, using that inverted index we built previously.
We then narrowed this list down to documents that contained every keyword in the query and ranked these documents by assigning weights. These weights were created based on a Best Match 25 (BM25) ranking algorithm, which considers a document’s term frequency, length, and inverse document frequency (reducing the “strength” of results that contain common terms, like “Aerospike” or “index”), and the average length of documents across the whole website. Documents were scored based on how the keyword appeared: e.g., highest for the title, somewhat lower for the description, and lowest for the content. We also implemented proximity scoring, giving a higher score to the documents that contained the search keywords in close proximity to each other. These ranking steps nominated the most relevant keyword results to pass to our final re-ranker.
By combining both vector and keyword search, we were able to both capture the broader context and intent with vector search and ensure we didn’t miss more “obvious” matches based on exact terms with keyword search.
Re-ranking
Now that we had two different lists of results from the keyword and vector search, we needed to find a way to combine them. This is when re-ranking stepped in; a second-stage re-evaluation and reordering of the results from our two separate retrievers. There are many algorithms and open-source models for re-ranking, and we tried several.
Our first attempt, using Google Cloud’s semantic re-ranker, worked. But we found that it was generally slow and would produce some irrelevant and–frankly–odd results. It seemed to undo all the work we had done on the original rankings.
We then looked at Cohere, which gave us better results than Google Cloud but still slowed down our search performance.
We ultimately decided to go with reciprocal rank fusion (RRF). RRF combines two ranked lists into one, giving greater final scores to documents ranked highly by the independent retrievers. Since we received good results from both vector and keyword search individually, using RRF was the most effective re-ranking method we found, combining and enhancing the strengths of each retriever into one final results list.
Front-end
Vaibhav and I don’t have a ton of front-end experience. Lucky for us, Art is a complete wizard at this. Most of this part was just watching him wave his magic wand and masterfully integrate our search application with the existing website. We liked Docusaurus’s UX design of an initial modal that popped up, giving us the top five results, and then a button to see the rest:
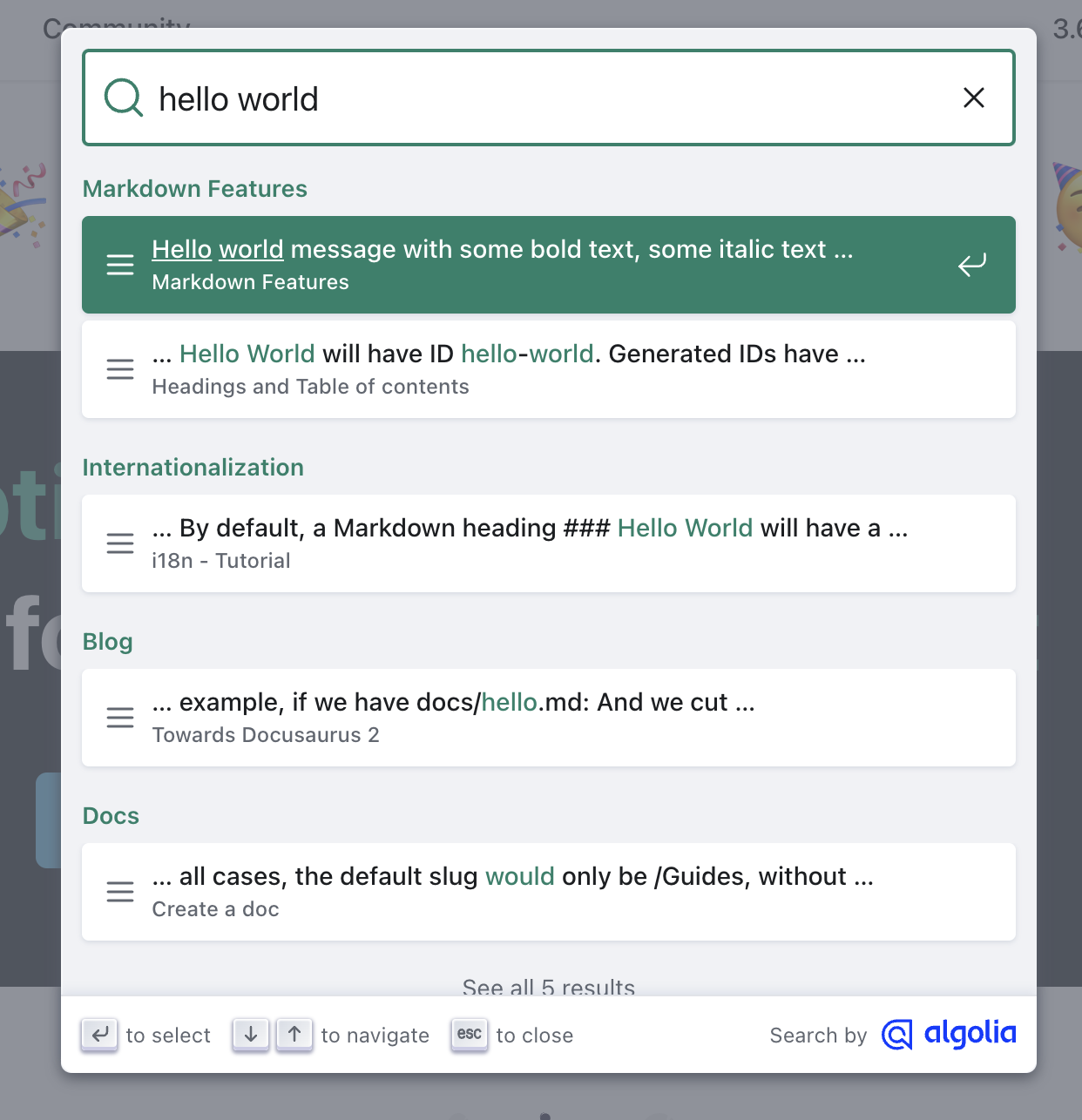
We re-created that for our search experience. The idea was that those top five results would be so relevant and helpful that the user would have no need to click to see the rest. This was our implementation:
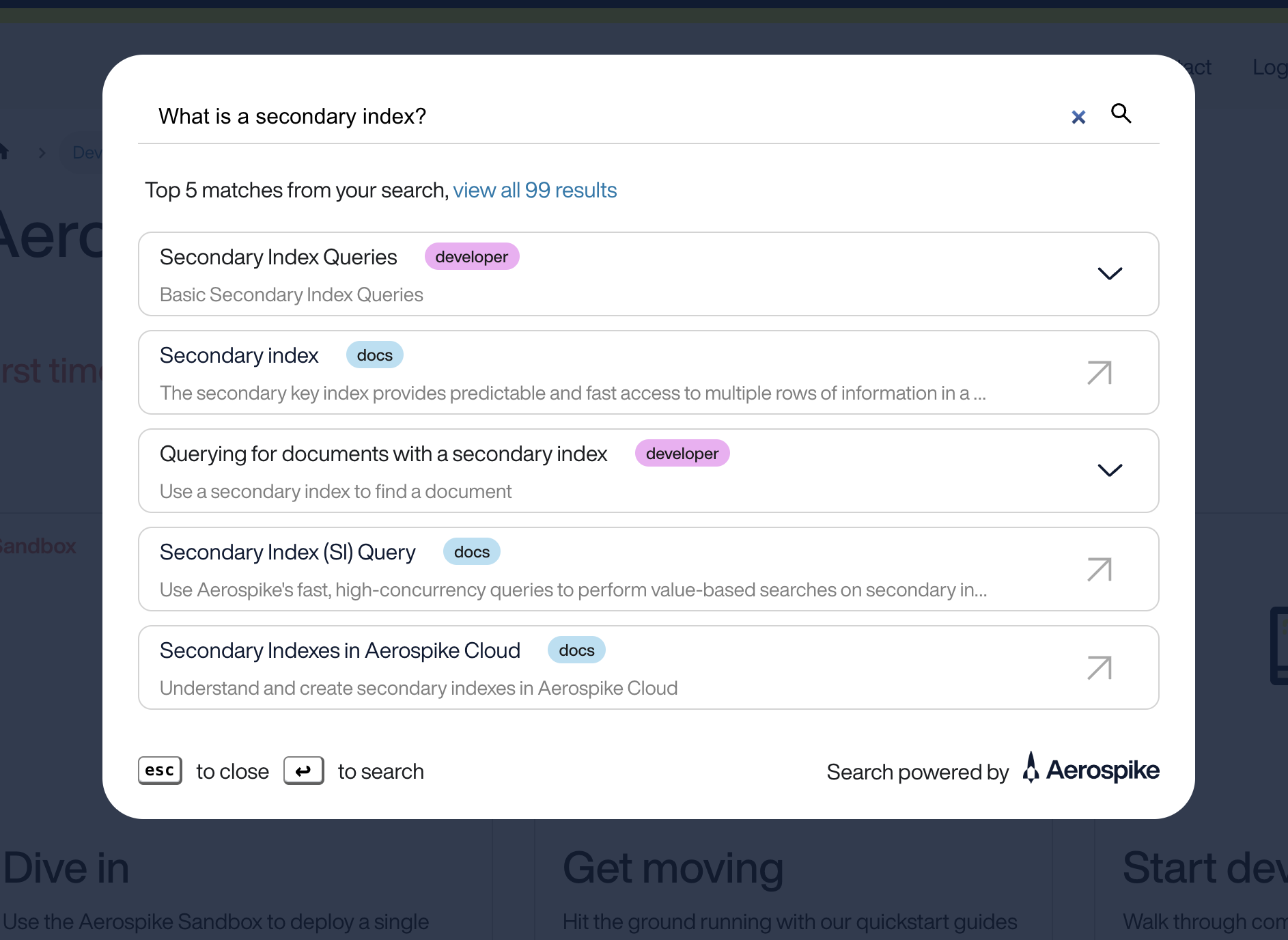
Since many of the developer pages had the same content for different client libraries, Art also created drop-downs to reduce the redundancy of the search results and implemented some helpful (color-coded!) filtering.
Hopeful next steps
Of course, all this work is just a start. There are still many routes we can take to improve search performance, such as returning a snippet of the query-related chunk to the search user or finding more efficient ways to scrape the Aerospike websites.
Our immediate priority (and fun project) is to use our search engine as the source for an AI chatbot, creating a conversational experience where users will be able to get expert answers instantly, right from Aerospike.com. Stay tuned!
Try out our search engine yourself.



