Wait, wait! What is strict serializability?
Learn how strict serializability ensures real-time order and integrity in distributed database systems, surpassing traditional isolation levels.

Many of you may not have heard of strict serializability, though you might be familiar with serializability and linearizability. In this blog, we explore why strict serializability represents the highest level of correctness for distributed databases, achieved by combining key concepts from serializability and linearizability.
Serializability and isolation levels
Serializability is the gold standard when it comes to isolation levels in databases and provides the guarantee that concurrent execution of transactions is equivalent to them executing in isolation one after the other in a database. On single-node, centralized databases, serializability allows the application programmer not to worry about potentially reading dirty data, losing their writes to the database, reading different data values when reading the same item twice, or reading some of the records written by a transaction but not others. It has been what database systems have aimed to provide application developers to ensure that, for example, bank balances don’t disappear, or that an assigned plane seat hasn’t been sold to someone else.
Linearizability and consistency levels
On the other hand, linearizability is the gold standard for consistency levels in distributed systems. These consistency levels are for the multiple copies (replicas) of a data item maintained by a distributed system to increase the availability of the data item. Linearizability gives the illusion to application programmers that there is exactly one copy of the data item and that all operations on the data item appear to happen in the same order for all the applications accessing that item. and further operations that start after another operation has completed will see the effects of that operation (operations respect real-time order).
Isolation levels and consistency levels have largely developed independently and in parallel. Isolation levels focus on transactions that access multiple records with only one copy. Consistency levels focus on operations that access a single data item with many copies. Historically, NoSQL databases retrieve a single key-value pair back from the database. However, they have been designed to maximize availability by allowing replicas of these key-value pairs while providing linearizability to their applications. On the other hand, relational databases, until recently, focused on transactions that involve multiple records and serializability, and replication has not been a focus.
For this blog, we will use the term distributed transactions to refer to transactions, each of which involves multiple records, and each record has multiple replicas. (As an aside, note that the term distributed transactions has also been used to refer to transactions in distributed databases that do not support replication.) In the last decade, we have begun to see practical systems implementing serializability and linearizability on multiple records for distributed transactions, bridging these traditionally different concerns.
Why is serializability not enough for distributed transactions?
Serializability guarantees that the concurrent execution of transactions is equivalent to transactions executing in some serial order. However, the definition allows an implementation a lot of latitude to find the equivalent serial order. In particular, transactions can "travel back in time" to make their execution serializable. In centralized databases with only one replica of a data item, there are not too many possibilities for a transaction to “travel in time, " but replication allows more such time travel possibilities, as we will show shortly.
Consider this contrived example: Suppose a database starts empty. If a system knows a transaction is read-only, it could return an empty result, effectively executing the read as if it occurred immediately after the database was created—before any writes took place. Another contrived example is an “immortal write,” in which a transaction that consists of a single operation that updates an existing record essentially does nothing - it pretends that it happened before the transaction that actually wrote the current value of the record. While no practical system would behave this way, it illustrates serializability's flexibility in determining the order of transactions. This flexibility leads to anomalies that are more plausible (and not as contrived) for distributed transactions. Below, we discuss two key anomalies: stale reads and causal reverse.
Stale reads
A stale read occurs when a read operation fails to see the effects of a write that has already completed. Many users have encountered this issue in everyday applications like email or photo-sharing services, where, for example, a friend shares an email or a photo, but it does not immediately appear on your device.
This happens in distributed databases that lack linearizability for reads of single data items. As shown in the figure below, suppose transaction T1 writes to item X but updates only one replica while other replicas receive the update asynchronously. Another transaction, T2, which reads X, begins after T1 has committed but accesses a stale replica. Since serializability only requires some equivalent serial order, this can still be valid—it corresponds to a schedule where T2 appears to execute before T1.
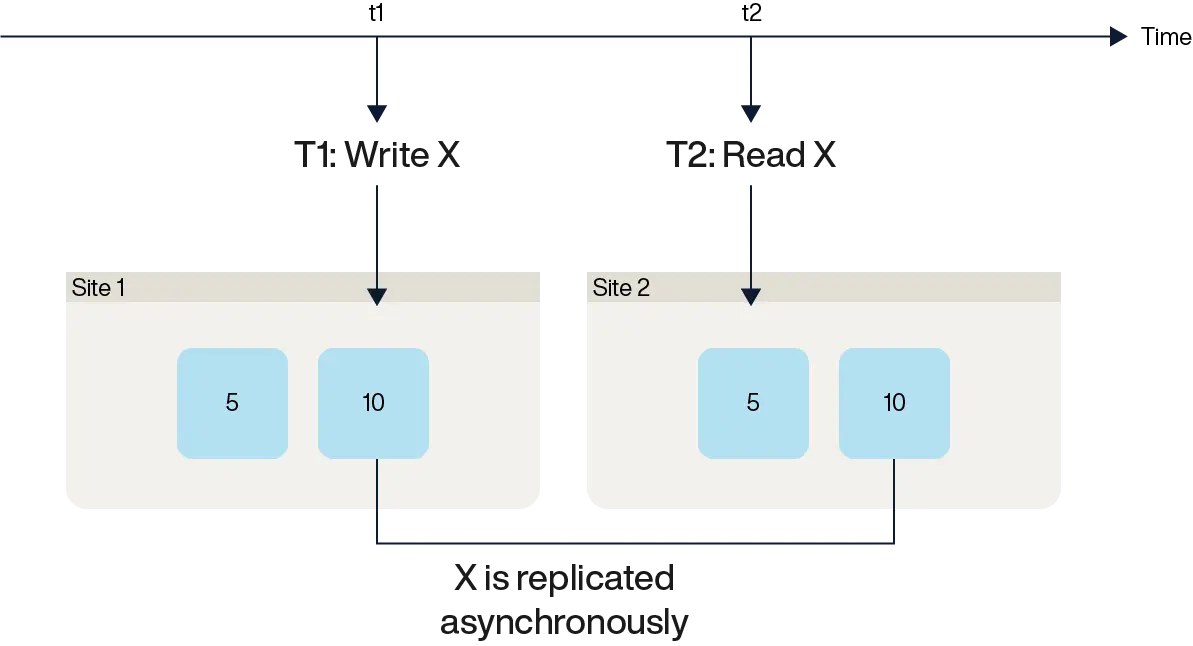
In a single-copy database, such anomalies do not occur, which is why they were historically overlooked in traditional database research. However, with replication becoming widespread in transactional databases, stale reads have become a critical issue.
Aside: Multi-version concurrency control (MVCC) also enables read-only transactions to "time travel" by reading historical versions of data based on timestamps, where each version is meant to have different values. However, MVCC deals with multiple versions of a data item within a single database node. In contrast, the anomalies discussed here arise from multiple copies of a data item across replicas that are supposed to remain consistent.
Causal reverse
Causal reverse arises when one transaction starts after another completes, yet a third transaction observes the second transaction's effects without seeing the first. Unlike stale reads, causal reverse can occur even when a database ensures linearizability for single-item reads and serializability for transactions.
A prototypical example involves two transactions, T1 and T2, where T2 begins only after T1 has completed, coordinated via an external communication mechanism. However, another transaction, T3, sees the effects of T2 but not T1, leading to an inconsistent view of the system.
Example 1: Bank transfers
Imagine you are at a bank in Italy and want to transfer $300K from your checking account (balance: $320K) to your friend’s account (T2). To ensure you maintain a minimum required balance across accounts, you call your spouse in the USA and ask them to deposit a $330K IRS tax refund into your savings account (balance: $10K) using their mobile app (T1). You proceed with the transfer only after your spouse confirms the deposit.
Meanwhile, a loan application (T3) checks whether your total account balance exceeds $300K. We know T1 completes before T2 starts. If T3 executes before T1, between T1 and T2, or after T2, it should see at least $300K across your accounts. However, if T3 observes T2 but not T1, it might incorrectly conclude that your total balance is below $300K.
Although this execution is still serializable—corresponding to the valid serial order T2 → T3 → T1—it contradicts real-time causality, leading to an incorrect outcome.
Example 2: Streaming service
Consider a streaming service where a family account allows only one active stream at a time. You are watching a movie and log out (T1). After informing your spouse, they log in from another city and start streaming their favorite show (T2).
Meanwhile, an automated audit transaction (T3) checks for simultaneous streams. If T3 sees T2 but not T1, it incorrectly detects two active streams and penalizes your account. Again, this schedule is serializable (T2 → T3 → T1), but it violates the expected causal order, leading to an erroneous penalty.
Why does this matter?
These anomalies lead to unexpected behavior, frustrating users and forcing developers to carefully design application logic to avoid such inconsistencies. Strict serializability eliminates this problem by ensuring transactions respect real-time order, making distributed databases more intuitive and reliable.
The interplay of serializability and linearizability
Before defining strict serializability, let’s summarize how serializability and linearizability interact and why they are insufficient on their own.
Linearizability does not guarantee serializability
This should come as no surprise, as linearizability only applies to operations on individual objects, not entire transactions. Consider the following schedule, which is not serializable, even if the system ensures linearizability for each object:
R(1,A),R(2,A),W(1,B),W(2,B)Here, transactions 1 and 2 read the same value of A, then write to B. If this were a serial execution, one transaction should have seen the other's write, but that doesn’t happen, violating serializability.
Serializability does not require linearizability
We previously reviewed stale reads, where a system achieved serializability despite lacking linearizability for single-item reads. This means transactions could be serialized in an order that allows reading outdated values, even if a more recent write had committed.
Serializability and linearizability together are also not enough
Even when a system ensures both serializability for transactions and linearizability for individual objects, anomalies can still occur. The causal reverse example demonstrated this: transactions respecting serializability and linearizability can still execute in an order that contradicts real-world causality, leading to inconsistencies.
Strict serializability
Now, we define strict serializability, the strongest correctness guarantee for distributed transactions. A database system is strictly serializable if:
It provides serializability, ensuring that transactions execute in an order equivalent to some serial execution.
It respects real-time order—if T1 completes before T2 starts, then the equivalent serial order must place T1 before T2.
A system that supports strict serializability prevents both stale reads and causal reverse, ensuring transactions behave as if they were executed one at a time, in real-time order, across all replicas.
Strict serializability and external consistency
Google’s Spanner made the term “external consistency” very popular. Although the informal language used to express external consistency slightly differs from the language used to express strict serializability, they boil down to the same correctness guarantee.
Reduced isolation and consistency levels with Aerospike
As we have seen, even the strongest isolation (serializability) and consistency (linearizability) guarantees combined can still result in an unexpected anomaly, such as a causal reverse. Despite this, many databases trade off correctness for performance, offering only reduced isolation levels, such as read committed or snapshot isolation, and weaker consistency levels, like causal consistency.
The interplay of these isolation and consistency levels creates a vast space of possible correctness models, and it gets complex for an application programmer to systematically map out which anomalies they must account for when using reduced guarantees.
We have built Aerospike Database 8's transaction capabilities into our existing high-performance NoSQL database, thus providing the best correctness guarantees, perhaps even at better performance than other databases can deliver at lower correctness levels.