Concurrency control in database management systems
Learn the importance of concurrency control in databases for managing concurrent transactions. Explore ACID compliance and concurrency control protocols.

This blog provides an introduction to transactions and how to implement concurrency control in DBMS (database management systems), which is essential for ensuring the correctness of concurrently executing transactions. Below, we explore the isolation property and how concurrency control ensures the correctness of concurrent transaction execution, thereby providing isolation.
ACID compliance overview
Transactions are characterized by the ACID properties:
Atomicity: Guarantees that either all actions of a transaction are visible to other transactions or none of them are.
Consistency: Ensures that transactions take the database from one consistent state to another. Consistency is defined by constraints such as primary key constraints (ensuring uniqueness of records), secondary indexes accurately reflecting updates, and referential data integrity constraints in relational databases.
Isolation: Ensures that even when transactions execute concurrently, they appear to execute in isolation from one another. Concurrency control mechanisms in a database help enforce this isolation.
Durability: Guarantees that once a transaction commits, its effects are permanent and not lost. In practice, systems are designed to withstand certain failures, such as disk or node failures. However, if all storage locations are lost, durability cannot be guaranteed. In the context of single-node databases, durability primarily refers to surviving node failures and restarts.
The importance of concurrency control in DBMS
High-performance databases routinely process millions of transactions per second by executing transactions concurrently, maximizing resource utilization (CPU, disk, network) and throughput while minimizing response time. However, to ensure predictable behavior, concurrent transaction execution must be carefully managed. Application developers expect database systems to provide correctness guarantees so they do not have to enforce them manually. For instance, users of applications on top of databases do not want their online orders to not be delivered, or other inconsistencies arising from concurrent execution.
Next, we explore what correctness guarantees mean in the context of concurrent transactions.
Correctness of concurrent execution of transactions
To understand the importance of concurrency control, let’s examine how interleaving the actions of database transactions can lead to undesirable outcomes if not managed properly.
Consider a database that allows reading and writing records identified by their primary keys. Suppose we have two interleaved transactions, T1 and T2, as shown in Table 1. T1 transfers $1,000 from account A to account B, while T2 reports the total balance of both accounts.
| Time | T1 | T2 |
|---|---|---|
|
t1
|
Read A
|
|
|
t2
|
A = A - $1,000
|
|
| t3 |
Write A
|
|
| t4 |
Read A; Read B, Print (A+B)
|
|
| t5 |
Read B
|
|
| t6 |
B = B +$1,000
|
|
|
t7
|
Write B
|
T2 executes all its actions between T1’s update of A and B and, therefore, reports the sum of the balances in the accounts to be $1,000 less than what it should be. Another way of thinking about this is that if we were to run these transactions one after the other, we would get the right result. It does not matter what order we run the transactions in; we will get the same result for T2. In general, running transactions in different order will leave the database in a different final state.
However, we understand serial execution of transactions. The goal of concurrency control is to ensure that when we interleave a transaction's execution, the resulting effect on the database and what is returned from the database is as though the transactions were executed serially, one after the other.
Schedules
A schedule is a time-ordered sequence of actions executed by transactions. While we included arithmetic operations in Table 1, they are not essential to understanding concurrency control. In reality, concurrency control mechanisms do not assume anything about an application's computations after reading an item.
We can represent Table 1 more compactly, using notation such as R(1, A) to denote transaction T1 writing A, as:
R(1,A), W(1,A), R(2,A), R(2,B), R(1,B), W(1,B)The above schedule is not equivalent to executing T1 and T2 serially in any order. This motivates the need for concurrency control to ensure correctness.
Serial schedule
A serial schedule is one in which all actions of one transaction execute before another begins. An example where T1 executes completely before T2:
R(1,A), W(1,A), R(1,B), W(1,B), R(2,A), R(2,B)Serializable schedules
Executing transactions one at a time is highly restrictive. Instead, databases ensure that interleaved execution produces results equivalent to some serial schedule. Such schedules are called serializable schedules. An example of a serializable but non-serial schedule is:
R(1,A), W(1,A), R(1,B), R(2,A), W(1,B), R(2,B)Here, T2 correctly computes the sum of A and B. This raises the question: how do we formally define when two schedules are equivalent? One common definition is conflict equivalence.
Two actions from different transactions conflict if they operate on the same item and at least one of them is a write. Read operations do not conflict, as their order does not affect correctness. Two adjacent actions in a schedule can be interchanged to produce an equivalent schedule if those actions do not conflict.
A schedule is conflict serializable if it can be made into a serial schedule by swapping adjacent non-conflicting actions. For example, in:
R(1,A), W(1,A), R(1,B), R(2,A), W(1,B), R(2,B)We can swap R(2, A) with W(1, B) to obtain a serial schedule. Thus, this schedule is conflict serializable. For the rest of this blog, “serializable” will refer to conflict serializable schedules.
SQL isolation levels and their evolution
Serializable schedules are the highest level of isolation a database system can guarantee. Many databases offer other lower levels of isolation as a way to tradeoff correctness guarantee for better performance. Read-only transactions or queries that are reading large amounts of data and computing aggregate statistics may benefit from lower levels of isolation. The SQL standard supports four levels of isolation:
READ UNCOMMITTED: The lowest isolation level, READ UNCOMMITTED, allows transactions to perform dirty reads.
READ COMMITTED: At this level, transactions can only read the committed values of other transactions. However, if the same item were to be read again in the transaction, there is no guarantee that the same value would be returned—that data item may have been modified between the two reads.
REPEATABLE READ: At this level, transactions can only read committed values, and these values will not change if they are re-read within the same transaction. However, the same query with a predicate that identifies the records it wants to read could return a different set of records (corresponding to newly inserted records by other transactions) if it were to execute twice within a transaction. This anomaly is called the “phantom read problem.”
SERIALIZABLE: This is the highest level of isolation and prevents dirty reads, ensures repeatable reads, and finally prevents phantom reads. This article focuses on serializability, but we introduce other isolation levels as they are useful for long queries in many applications.
Precedence graph
A precedence graph helps determine if a schedule is serializable. Given a schedule, we can construct a precedence graph as follows.
Each transaction is a node.
If two actions conflict and the action from T1 precedes the one from T2, draw an edge from T1 → T2.
If the graph has a cycle, the schedule is not serializable.
The precedence graph for the schedule is shown below:
R(1,A), W(1,A), R(2,A), R(2,B), R(1,B), W(1,B)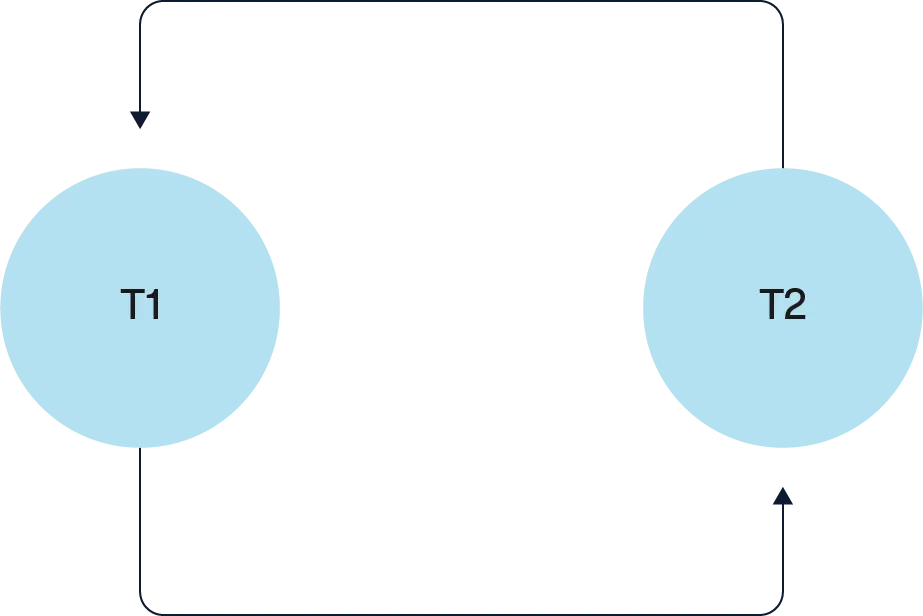
It has two edges:
T1 → T2 (due to W(1, A) → R(2, A))
T2 → T1 (due to R(2, B) → W(1, B))
Since this forms a cycle, the schedule is not serializable.
Precedence graphs provide a formal tool to verify the correctness of concurrency control mechanisms. The algorithms we discuss next ensure no cycles occur, thereby guaranteeing serializability.
Concurrency control protocols
In the previous section, we defined correctness for concurrent transaction execution and introduced the precedence graph, which provides a systematic way to determine whether a schedule is serializable. However, in real-world databases, transactions can begin at arbitrary times, and their actions are unknown in advance. In short, we cannot evaluate an entire schedule beforehand to determine its serializability. Instead, the database system must dynamically enforce serializability as transactions execute.
This section explores four broad classes of concurrency control algorithms, each differing in how they handle transaction actions as they are submitted.
Two-phase locking
Two-phase locking (2PL) is one of the most widely used concurrency control protocols, particularly in centralized, single-node relational databases. It requires transactions to acquire locks before accessing data. Lock-based protocols, in general, obtain a lock before they operate on an item. 2PL is a type of lock-based protocol that employs two types of locks:
Read lock (shared lock): Allows multiple transactions to read an item simultaneously.
Write lock (exclusive lock): Prevents other transactions from acquiring any lock (read or write) on the same item.
This locking behavior aligns with the notion of conflicts introduced in the previous section.
2PL consists of two phases:
Growing phase: The transaction acquires locks but does not release any.
Shrinking phase: Once a transaction releases a lock, it cannot acquire any new locks.
The moment when a transaction has acquired all its required locks is known as the lock point. The schedule produced by 2PL is equivalent to a serial schedule where transactions are ordered by their lock points.
Strict two-phase locking (Strict 2PL)
In standard 2PL, a transaction releases locks as soon as the locks are no longer needed once the transaction has reached its lock point. These can lead to schedules that are not recoverable or cause cascading aborts as described below:
The schedule is not recoverable: A committed transaction may have read values written by another transaction that later aborts. This is not a desirable situation.
Schedule causes cascading aborts: The failure of one transaction may force multiple dependent transactions to abort.
Most databases implement strict 2PL to mitigate these issues, where all locks are held until the transaction commits or aborts.
Deadlocks in 2PL
When a transaction attempts to acquire a lock held by another transaction, it must wait. This waiting can create cyclic dependencies, leading to deadlocks, where two or more transactions wait indefinitely for each other’s locks.
Databases handle deadlocks in two ways:
Timeout-based detection: Transactions waiting longer than a configured threshold are aborted to break potential deadlocks.
Deadlock detection and resolution: The system detects deadlocks and aborts one of the involved transactions to resolve the deadlock.
2PL and the precedence graph
For any two concurrently executing transactions, 2PL enforces a precedence relationship: If one transaction waits for a lock held by another, an edge will get created in the precedence graph, after the second transaction obtains the lock. Since a transaction can only release locks after acquiring all necessary locks, the precedence graph remains acyclic, ensuring serializability.
Optimistic concurrency control (OCC)
Two-phase locking (2PL) is often referred to as a pessimistic concurrency control mechanism because it prevents conflicts entirely by requiring transactions to acquire locks before accessing data. In contrast, optimistic concurrency control (OCC) takes the opposite approach: it allows transactions to execute concurrently without restrictions, resolving conflicts only at commit time by ensuring that the final schedule remains serializable.
Mechanism of optimistic concurrency control
OCC maintains a read set and a write set for each transaction:
Read set: Tracks all items read by the transaction, along with their version numbers.
Write set: Contains all items modified by the transaction in a private copy.
Each data item has a version number that is incremented whenever a committed transaction updates the item.
OCC consists of two main phases:
1. Execution phase
Transactions execute independently and concurrently.
When a transaction reads an item, it records the item’s version number in its read set and caches the value locally.
When a transaction writes an item, it modifies a private copy rather than directly updating the database.
2. Validation and write phase
Transactions enter this phase one at a time, ensuring serialized validation and write phases.
A timestamp is assigned to the transaction upon entering this phase.
The system validates whether the transaction reads remain consistent by checking that the version numbers of all read set items have not changed since they were read. This ensures the transaction has not read stale data.
If validation succeeds, the transaction's writes are committed to the database, and the affected items’ version numbers are updated with the transaction's timestamp. If validation fails, the transaction is aborted and must be retried.
Properties of OCC
OCC is particularly effective when conflict rates are low, as it allows a high degree of concurrency without requiring transactions to wait for locks. However, if conflicts are frequent, OCC can lead to higher abort rates due to failed validation, making it less efficient than pessimistic approaches like 2PL.
Timestamp based protocols
In a timestamp-based protocol, each transaction T is assigned a unique, monotonically increasing timestamp, TS(T), upon entering the system. This timestamp can be derived from a logical counter that increments with each new transaction. The protocol ensures the resulting schedule is equivalent to a serial execution ordered by transaction timestamps.
Mechanism
Each data item maintains two timestamps:
Read timestamp (RTS): The largest timestamp of any transaction that has successfully read the item.
Write timestamp (WTS): The largest timestamp of any transaction that has successfully written the item.
The execution rules are as follows:
Read operation: A transaction T can read an item X only if WTS(X) ≤ TS(T) (i.e., the item was last written by an earlier or the same transaction). If the read is successful, RTS(X) is updated to max(RTS(X), TS(T)).
Write operation: A transaction T can write an item X only if RTS(X) ≤ TS(T) and WTS(X) ≤ TS(T) (i.e., no transaction with a later timestamp has read or written the item). If the write is successful, WTS(X) is updated to TS(T).
These rules ensure that transactions execute in a manner consistent with their timestamp order, thereby guaranteeing serializability.
Practical considerations
Pure timestamp-based protocols are rarely used in isolation due to their overhead, particularly the need to maintain and update timestamps even for read operations. However, the concept of assigning timestamps to data items and transactions is fundamental to multi-version concurrency control (MVCC), a widely used approach that we will discuss next.
Multi-version concurrency control (MVCC)
As the name suggests, multi-version concurrency control (MVCC) maintains multiple versions of a data item. There are two primary flavors of MVCC: one based on timestamp ordering and another based on 2PL. This discussion focuses on the 2PL-based MVCC, which is widely used in modern distributed databases.
In this variant, each version of a data item is associated with a write timestamp, but read timestamps are not required. Transactions are categorized as either read-write transactions or read-only transactions. A global timestamp counter is used to assign timestamps:
Read-write transactions receive a timestamp when they commit.
Read-only transactions receive a timestamp when they start.
The execution under this protocol ensures serial equivalence, where transactions appear to execute in timestamp order.
Execution of read-write transactions
Read-write transactions follow the 2PL protocol with additional versioning mechanics:
When a transaction first writes a data item, it creates a new version with a tentative write timestamp set to infinity.
Reads always fetch the latest committed version of a data item.
At commit time, the transaction:
Acquires an exclusive lock on the global timestamp counter
Assigns itself a commit timestamp
Updates the write timestamps of all versions it has created to this commit timestamp
Releases the lock on the global timestamp counter only after updating all written versions
Execution of read-only transactions
Read-only transactions operate without acquiring locks:
At start time, they receive a timestamp from the global timestamp counter.
Since they do not modify data and will precede all read-write transactions that are yet to commit, they do not need to account for concurrent read-write transactions.
When reading a data item, they fetch the latest committed version whose write timestamp is smaller than or equal to their assigned timestamp.
Advantages of MVCC
Read-only transactions always succeed and execute without blocking or interfering with read-write transactions.
Read-write transactions use standard 2PL, which is well-tested and reliable, with minor additions for versioning.
Optimized for workloads with frequent reads, as readers never block writers, and vice versa.
Aerospike approach to concurrency control in transactions
Aerospike employs a hybrid approach (described here in detail) to concurrency control, combining optimistic concurrency control (OCC) for reads and strict 2PL for writes. This design optimizes performance by avoiding locks for reads while ensuring correctness through locking for concurrent writes.
Reads operate optimistically, proceeding without acquiring locks. At commit time, the system verifies that the read values remain the latest versions using version numbers—a mechanism already maintained as part of Aerospike’s strong consistency protocol.
Writes follow strict 2PL, where only one active writer is allowed per data item at a time. If multiple transactions attempt to modify the same item, the system enforces mutual exclusion via locks. In contrast, a pure OCC approach would require one of the conflicting transactions to fail after executing the transaction to completion unless most writes were blind writes (i.e., writing without reading the existing value).
The moment a transaction commits can be interpreted as its logical timestamp for reasoning about serial equivalence. However, unlike traditional timestamp-based protocols, Aerospike does not require a global timestamp counter, which could become a performance bottleneck.
To ensure atomicity, isolation, and durability, writes in Aerospike:
Update a provisional copy of the data item.
Use this provisional copy as a redo and undo log, enabling efficient rollforward or rollback operations.
Unlike multi-version concurrency control (MVCC), Aerospike does not maintain multiple versions of a data item. However, Aerospike does maintain multiple copies (not versions across time) of a data item for availability.
Key takeaways on concurrency control in databases
In this blog, we have examined the importance of concurrent transaction execution for maximizing database performance. We have established a framework for reasoning about correct interleavings of transactions and introduced the concept of serializability. We then explored four widely used concurrency control protocols in the database industry that guarantee serializability.
As for next steps, we encourage you to read about how distributed systems guarantee consistency of replicas of a data item. The highest form of consistency for replicas in a distributed system is called linearizability. Finally, we encourage you to read about strict serializability, which builds on linearizability and serializability to guarantee the highest correctness level for distributed transactions that span multiple records, with each record having many replicas.