Connection tuning guide
This page describes the client-side parameters you can adjust to optimize your application's speed and reliability.
Client tuning parameters
socketTimeout
Description: Triggers a client-side timeout when a socket exceeds this
value in idle time (ms).
Why use it? Adjust this paramter in your client applications based on what you
expect in terms of server-side response latency. Increased latency in server-side
responses can occur either because the server is saturated and having trouble keeping
up with requests, or because you are having network connection issues. In both cases,
if you expect longer latencies you should increase this paramater accordingly to avoid
unnecessary failures due to timeout. However, don't make it longer than necessary,
because excessively long timeout intervals can cause error detection and SLA violations
to take longer to trigger alarms.
Policy type: base policy
Java/C# name: socketTimeout
Go name: SocketTimeout
Python name: socket_timeout
Related parameters and dependencies:
maxRetriessleepBetweenRetriestotalTimeouttimeoutDelaytransaction-max-ms(server-side)
Notes: Note on multi-record requests: requests that return multiple records in the response can possibly trigger a timeout even if there are no functional issues. For example, a primary index query with a filter may still trigger the timeout even if the final result set is small because the intermediary result sets still take time to process on the server side. Be careful of this and increase timeout values accordingly.
totalTimeout
Description: Client-side timeout when the total amount of time spent without completing
a request exceeds this value (ms).
Why use it? Use this parameter when you have a business logic need to cut off
the command. This timeout overrides any combination of retries that happen
after a series of socket timeouts. For example, you may cut out quicker and not
reach the maxRetries limit if the (socketTimeout + sleepBetweenRetries)
x maxRetries > totalTimeout.
In some cases, it may be better for your application to trigger a timeout to
prevent losing a connection. In this situation, you may also want to take a look
at the timeoutDelay policy parameter (Java Client only).
For batched commands, you may also want to consider having the application
itself retry the command. This may be preferable to hitting a client total
timeout and then splitting up a large batch, depending on the situation.
Policy type: base policy
Java/C# name: totalTimeout
Go name: TotalTimeout
Python name: total_timeout
Related parameters and dependencies:
maxRetriessleepBetweenRetriessocketTimeouttransaction-max-ms(server-side)
Notes: totalTimeout does not include time taken to open a connection
(the time considered with the connectTimeout policy option).
The totalTimeout value is sent to the Aerospike server. This is typically set to
something higher than the value of socketTimeout to allow for socket request retries.
If this parameter is set to a value greater than zero, be aware you can get a
general timeout raised either from the client-side or the server-side (via
the transaction-max-ms) setting.
maxRetries
Description: Total number of times to retry a request after a timeout or error
is detected from the server.
Why use it? Increase this parameter if your environment has unreliable connections or
a server that is at or near its capacity.
You should consider whether or not retries will actually help before you adjust this parameter.
Examples of when retries can help:
- Unreliable network connections.
- Server occasionally has its request queues filled to capacity because all clients are trying to hit it at the same time, but the high traffic time periods are short and periodic.
- Some network and/or node unreliability with a replication factor of 2 or more, in which case the retry can be redirected to the replica node.
Examples when retries may not help:
- Server’s request queues or other resources are saturated most or all of the time.
- Saturation issues due to bad data distribution.
- Any sort of error that is caused by a systemic and/or permanent failure on the node.
Policy type: base policy
Java/C# name: maxRetries
Go name: MaxRetries
Python name: max_retries
Related parameters and dependencies:
sleepBetweenRetriestotalTimeoutsocketTimeout
Do not use this for non-idempotent writes, as this can cause you to unintentionally write the same record multiple times.
Note that adjusting this parameter can be a band-aid solution. Needing a very high number of retries to stabilize your application may indicate you need more server-side capacity, or you have some sort of node imbalance.
Also, having a high number of retries can cause connection pileup.
sleepBetweenRetries
Description: Time to wait before retrying a request (ms).
Why use it? Increase this if your applications retry requests frequently
and there is concern about connection pileup.
If you use this, you should set it to be about 50% of your anticipated cluster reformation time.
Policy type: base policy
Java/C# name: sleepBetweenRetries
Go name: SleepBetweenRetries
Python name: sleep_between_retries
Related parameters and dependencies:
maxRetries
Notes: The sleep interval only occurs on connection errors and server timeouts
which suggest a node is down and the cluster is reforming. The sleep interval does
not occur when the client's socketTimeout expires.
Reads do not have to sleep when a node goes down because the cluster does not shut out reads during cluster reformation. The default for reads is zero.
The default for writes is also zero because writes are not retried by default.
Writes need to wait for the cluster to reform when a node goes down. Immediate
write retries on node failure have been shown to consistently result in errors.
If maxRetries is greater than zero on a write, then sleepBetweenRetries should be
set high enough to allow the cluster to reform (>= 3000ms).
This setting is ignored in async mode for single record command requests, but is supported for async scans and queries.
Adjusting this parameter can be a band-aid solution, with the root problem being that you may need more server-side capacity or have a node imbalance.
SleepMultiplier
Description: Multiplying factor for exponential backoff of request retries.
Why use it? Increase this parameter to activate exponential backoff, which will
space out retries longer if the requests keep timing out.
Policy type: base policy
Java/C# name: N/A
Go name: SleepMultiplier
Python name: N/A
Related parameters and dependencies:
sleepBetweenRetries
Notes: Go only.
connectTimeout
Description: Time to wait for a connection to be opened before timing out (ms).
Why use it? This parameter can be thought of as a "carve out", that is, giving
an additional timeout length to apply to creating a new connection to add to the
connection pool if one is not available (or if we are initiating the app). This
is useful when we know that the time needed to establish a connection is long,
but we still want to be more aggressive with regards to timeouts once the connection
is established. TLS (encrypted) connections are a good example of where this can
be useful, because they take longer to initialize.
Policy type: base policy
Java/C# name: connectTimeout
Go name: N/A
Python name: N/A
Related parameters and dependencies:
totalTimeoutsocketTimeout
timeoutDelay
Description: Delay time (ms) after a socketTimeout or totalTimeout to attempt
to recover the connection.
Why use it? After a socket read timeout or total timeout, if this parameter
is set to a non-zero value, the client attempts to drain the socket of all data.
If the socket is successfully drained of all data prior to reaching the timeoutDelay,
the connection is returned to the pool. If not, the socket is closed and removed from
the connection pool. The primary purpose of this is to avoid performance penalties
that may occur if you attempt to close a non-empty socket. This can be especially
important if you are using a cloud provider.
Policy type: base policy
Java/C# name: timeoutDelay
Go name: N/A
Python name: N/A
Related parameters and dependencies:
socketTimeoutNotes: Java only.
Note that while this has benefits in a cloud environment, there is a penalty to pay in terms of memory and processing resources on the client to keep the sockets alive longer while attempting to drain them.
This setting is much more effective when used with Aerospike Server 6.0 and later, due to server-side improvements increasing the frequency of checking to allow for socket recycling.
maxSocketIdle
Description: Time (in seconds) a socket can remain idle before the connection is
closed and removed from the pool.
Why use it? Increase this parameter to decrease connection open/close thrash if
your workload level fluctuates.
Policy type: client policy
Java/C# name: maxSocketIdle
Go name: IdleTimeout
Python name: max_socket_idle
Related parameters and dependencies:
proto-fd-idle-ms(server-side)
Notes: This setting has been deprecated in favor of
minConnsPerNode to maintain a minimum number of active connections and avoid
incurring ramp up time after a low activity interval. If using minConnsPerNode,
this setting and the server setting proto-fd-idle-ms should be set to zero.
If the server setting proto-fd-idle-ms is greater than zero, this parameter
should always be set to a few seconds less than proto-fd-idle-ms to avoid
using a socket that has been reaped server-side.
Increasing this parameter will cause you to consistently use more client-side resources, so be careful if that is a concern.
maxConnsPerNode, asyncMaxConnsPerNode
Description: Ceiling limit for the total number of connections allowed per client, per node.
Why use it? Use as a preemptive means to limit the load
a client can send to the server. It can also be used as a way to limit exceeding
client-side resources.
If you set this to this to the same value as minConnsPerNode, you can
effectively fix the amount of open connections you have to that value.
Policy type: client policy
Java/C# name: maxConnsPerNode, asyncMaxConnsPerNode
Go name: ConnectionQueueSize, LimitConnectionsToQueueSize
Python name: max_conns_per_node
Related parameters and dependencies:
proto-fd-idle-msmaxSocketIdleminConnsPerNode
Notes: Note that connections used includes those for primary commands as well as parallel sub-commands from batch and query. This means you can consume more connections than you realize if you are making heavy use of batch, scan, or query operations.
minConnsPerNode
Description: Floor limit for the total number of connections per client, per node.
Why use it? Use this parameter if you want to avoid the ramp-up costs of creating
connections again on a live application that may sometimes have long idle periods.
This can also effectively reduce your connection startup latencies if your minConnsPerNode
is set to something approaching what would be your stable state active connection pool size.
Policy type: client policy
Java/C# name: minConnsPerNode, asyncMinConnsPerNode
Go name: MinConnectionsPerNode
Python name: min_conns_per_node
Related parameters and dependencies:
proto-fd-idle-msmaxSocketIdlemaxConnsPerNode
Notes: It is highly recommended to set maxSocketIdle and server-side proto-fd-idle-ms
to zero if minConnsPerNode is greater than zero.
If not set to zero, proto-fd-idle-ms must be set to a high enough number so that you
will not kill off the connections server-side while trying to use this feature.
For clarity: if you use minConnsPerNode, the connection pool gets populated
during the client initialization, prior to any request. This has the same effect as doing a manual warmup of the connections.
Warmup()
Description: Method that pre-fills the connection pools with live connections.
Why use it? You can use this method prior to sending real requests to avoid
the situation of having the first requests that are sent when an app starts
seeming to take longer than normal, because they will not need to wait for
the connection to initialize before executing the main request.
This is useful for customers who want to avoid triggering SLA violation alarms immediately after an application is restarted/bounced.
This can also be useful in benchmarking situations so you won’t count connection initialization costs in the main workload measurements.
Setting minConnsPerNode to a value approximating your anticipated typical
connection pool size has a similar effect to calling WarmUp() on initialization.
You may want to consider using that policy instead.
Policy type: N/A
Java/C# name: N/A
Go name: Client.WarmUp(), Node.WarmUp(), Cluster.WarmUp()
Python name: N/A
Related parameters and dependencies:
minConnsPerNode
Notes: Go only. Not a parameter, but rather a method.
For those clients that do not support WarmUp() you can use the MinConnsPerNode
policy if you want to pre-populate connection pools and are willing to commit fixed
resources on your application machine. To do so, set MinConnsPerNode to a value near
your average anticipated working connection pool size.
MinConnsPerNode is the preferred/recommended way to ensure you have some
initialized connections. The main difference between WarmUp and MinConnsPerNode
is that with WarmUp, the application developer has direct control over exactly
when the connections are initialized. If you are using minConnsPerNode, the
connections are not initialized until a Client tend thread event loop has completed
(see tendInterval).
maxErrorRate
Description: Max errors allowed per node per errorRateWindow before backoff is
initiated.
Why use it? This parameter, in conjunction with errorRateWindow, activates
circuit breaker functionality. The default setting is 100. Setting this value at the client level
can prevent a feedback loop where clients repeatedly open new connections to maintain throughput.
If the server struggles to handle these connections, clients continue opening more connections,
compounding the issue. By setting this threshold, each client takes a short pause
when it experiences rapid connection failures, allowing the server to process
connections at a manageable rate instead of facing a surge when it’s already overloaded.
This setting permits up to maxErrorRate errors per errorRateWindow (1 second by default)
per server node, after which the client will “back off” for the remainder of that window.
Policy type: client policy
Java/C# name: maxErrorRate
Go name: MaxErrorRate
Python name: max_error_rate
Related parameters and dependencies:
errorRateWindowtendIntervalsocketTimeouttotalTimeoutmaxRetries
Notes: For the error calculation, timeouts and critical server-side errors such as IO failures are counted. User errors such as “key not found” errors are not counted.
Note that changing timeout and retry behavior can affect when the circuit breaker kicks in, so make sure to evaluate this setting as well if you are tuning those parameters.
Trade-offs: Setting max_error_rate too low can make clients overly cautious, pausing work during transient errors. Setting it too high, however, risks a feedback loop where clients demand more connections than the server can handle, causing a global slowdown. The defaults are typically suitable, but with thousands of clients, a lower max_error_rate such as 10, is advisable. Adjustments can be fine-tuned based on how errors affect connection rates, with support staff available for guidance.
errorRateWindow
Description: Number of cluster tend iterations to use to evaluate maxErrorRate.
Why use it? This parameter adjusts the length of the window used to evaluate
whether or not to activate the circuit breaker. This parameter allows you to
control the needed error density in order to trigger client backoff.
Policy type: client policy
Java/C# name: errorRateWindow
Go name: ErrorRateWindow
Python name: error_rate_window
Related parameters and dependencies:
maxErrorRatetendInterval
tendInterval
Description: Amount of time between cluster tends (ms).
Why use it? This parameter, in conjunction with errorRateWindow, allows you
to control how long the error evaluation window is.
Policy type: client policy
Java/C# name: tendInterval
Go name: TendInterval
Python name: tend_interval
Related parameters and dependencies:
errorRateWindow
Notes: Note this setting not only affects the errorRateWindow, but also the
general frequency at which the client recognizes a change in the cluster status.
If you are just trying to change circuit breaker behavior, it's better to adjust
the errorRateWindow.
Server tuning parameters
proto-fd-idle-ms
Description: Time in milliseconds to wait before reaping connections. The default means that idle connections are never reaped. The Aerospike server uses keep-alive for client sockets.
Related parameters and dependencies:
maxSocketIdle
Notes: See the configuration reference for more information.
transaction-max-ms
Description: How long to wait for success, in milliseconds, before timing out
a command on the server, typically, but not necessarily, during replica
write or duplicate resolution. This is overwritten if the client command
timeout is set. Commands taking longer than this time, or the time
specified in the client policy, return a timeout and tick the
client_write_timeout metric.
Related parameters and dependencies:
socketTimeouttotalTimeout
Notes: See the Configuration reference for more information.
By default, short queries have a default 1 second socket timeout. See Queries, long and short for more information.
Timeout visualization
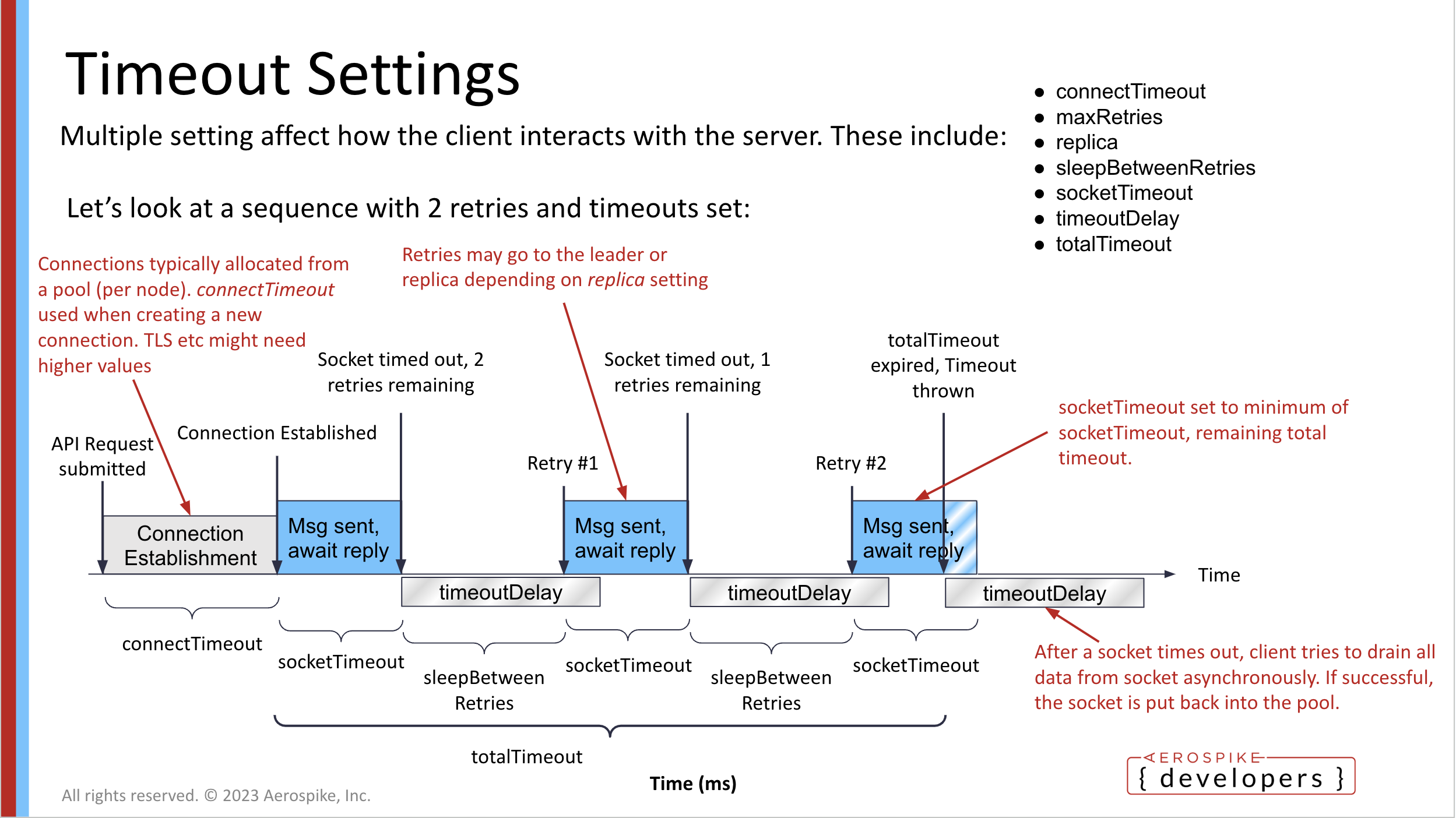
Common problems and solutions
Problem: Client connection churn - unrecoverable error state when server permanently falls behind client requests due to temporary degradation in server or network response time.
Solution: Use circuit breaker functionality to prevent the system from getting into the metastable failure state by causing the client to back off when degradation is observed via increase in errors/timeouts.
Use maxConnsPerNode to throttle client traffic by limiting the total
number of connections.
If available, use timeOutDelay to help recover connections more
quickly, especially in a cloud environment.
Relevant parameters:
maxErrorRateerrorRateWindow
Problem: Excessive client initialization load on server (“thundering herd”).
Solution: Use circuit breaker functionality to prevent system from getting into the metastable failure state by causing the client to back off when degradation is observed via increase in errors/timeouts.
Go client only: activate exponential backoff functionality.
Relevant parameters:
maxErrorRateerrorRateWindowSleepMultiplier(Go only)
Problem: Flow control issues on socket due to client slowness in processing responses.
Solution: Decrease maxConnsPerNode to throttle outgoing requests.
Implement app-side backoff logic if response handling queues in your app are getting filled.
Add more clients to increase your client-side resources.
Relevant parameters:
maxConnsPerNode
Problem: Frequent socket and/or total timeout errors during normal application operation.
Solution: Increase timeout lengths and possibly number of max retries to give the server more chances to return a response.
This issue may indicate that you have either an unstable network or a server-side capacity issue.
Relevant parameters:
socketTimeouttotalTimeoutmaxRetriestimeoutDelay(Java only)
Problem: Timeout errors on application initialization, but no timeouts after the app ramps up.
Solution: Set the connectTimeout parameter.
Relevant parameters:
connectTimeout
Problem: SLA violations on a periodically idle application.
Solution: Set minConnsPerNode to a value greater than zero.
Relevant parameters:
minConnsPerNode
Further reading
| Document | Description |
|---|---|
| Client Policies | Aerospike policy documentation |
| Java Policy definition | Source code for Aerospike Java client Policy.java |
| Java ClientPolicy definition | Source code for Aerospike Java client ClientPolicy.java |
| High client connections on certain nodes due to underperformance | Knowledge Base article discussing high client connection pileup if cluster nodes get slow and how to deal with it. |
| How can the actual Batch timeout be greater than the Batch TotalTimeout policy? | Knowledge Base article discussing Batch timeout and Batch TotalTimeout. |
| What happens to a batch request when batch sub-transactions time out | Knowledge Base article discussing what happens to batch when sub-transactions time out. |
| How to delay idle connections reaping | Knowledge Base article discussing avoiding unnecessary reaping of connections. |