Consistency
This page describes Aerospike's different consistency modes, Available and Partition-tolerant (AP) mode (a.k.a. High Availability) and Strong consistency (SC) mode. See Strong consistency for instructions on how to use SC mode.
Overview
A namespace's default mode is AP mode, which offers high availability at the expense of consistency during cluster partitioning events.
When a namespace is configured in SC mode, Aerospike ensures that writes acknowledged as successfully completed to the client are never lost due to cluster partitioning events. Strong consistency mode is comparable to CP mode of the CAP theorem (Consistency, Availability, and Partition-tolerance). Reads in SC mode, on a per-read basis, can be configured for session consistency or global linearizability.
Session consistency is the default SC read mode and it ensures that a client always reads its latest write to a record. Global linearizibility in SC read mode ensures that a client reads the latest version of the record written or updated by it or by any other client. The level of consistency is determined by the application logic through the use of policies. The SC read mode policy offers two consistency options for reads that are more relaxed. ALLOW_REPLICA allows reads from replica partitions and ALLOW_UNAVAILABLE allows reads from unavailable partitions. Each of these relaxed consistency options carries an increased risk of reading stale reads.
AP mode
As a distributed database, Aerospike provides automatic data replication.
For more information, see Data Distribution.
Aerospike is often configured to keep two copies of each record, a master copy and one replica copy,
by setting the namespace
replication-factor (RF) to 2.
Aerospike clients, being aware of the cluster's nodes and its partition map, send record write operations directly to the cluster node that owns the master partition of that record. The Aerospike node writes the record locally, and then synchronously performs replica writes. In the event that a network partition occurs, a namespace configured to be in high availability mode prioritizes availability over consistency; every sub-cluster allows reads and writes to be performed against the namespace data.
Aerospike client-server policies provide per-transaction controls over several read and write behaviors. By default:
The client first tries to read a record from the node that owns its master partition. If this operation times out, the client retries the read against another node that owns one of the record's replica partitions, which risks a stale read. This behavior is controlled by the replica policy. Write transactions always go to the node with the record's master partition.
The client only consults a single replica when performing a read transaction against a rebalancing cluster. This behavior is controlled by the client's AP read mode. The alternative policy setting risks stale reads, but runs faster and performs less read IO.
Write transactions, including deletes and calls to user-defined functions (UDFs), waits for the partition master both to write locally and finish its replica writes to other nodes before confirming that the write operation was successful. The client's write commit level policy controls this behavior. The alternative policy setting doesn't wait for replica-writes to successfully complete, and risks losing the write if the node holding the master replica goes down.
While these policies achieve a good level of consistency in a stable cluster, during network partitions or events when more than RF nodes are down, some writes might be lost and strong consistency violations such as stale reads might occur on read operations. Applications that do not tolerate such outcomes should store their data in a namespace configured with strong-consistency true.
For maximum flexibility, application developers can modify policies per-transaction.
SC mode
SC is available only in Aerospike Database Enterprise Edition and Aerospike Cloud Managed Service.
Aerospike's SC guarantee states that all writes to a single record will be applied in a specific order (sequentially), and writes will not be re-ordered or skipped.
In particular, writes that are acknowledged as committed have been applied, and exist in the transaction timeline in contrast to other writes to the same record. This guarantee applies even in the face of network failures, outages, and partitions. Writes which are designated as "timeouts" (or "InDoubt" from the client API) may or may not be applied, but if they have been applied they will only be observed as such.
Aerospike's SC guarantee is per-record, and involves no multi-record transaction semantics. Each record's write or update will be atomic and isolated, and ordering is guaranteed using a hybrid clock.
Aerospike provides both full Linearizable mode, which provides a single linear view among all clients that can observe data, as well as a more practical Session Consistency mode, which guarantees an individual process sees the sequential set of updates. These two read policies can be chosen on a read-by-read basis, thus allowing the few transactions that require a higher guarantee to pay the extra synchronization price, and are detailed below.
In the case of a timeout return value - which could be generated due to
network congestion, external to any Aerospike issue - the write is guaranteed to
be written completely, or not written at all; it will never be the case that the
write is partially written (that is, it can never be the case that at least one
copy is written but not all replicas are written). In case of a failure to replicate a write transaction
across all replicas, the record will be in the 'un-replicated' state, forcing a 're-replication'
transaction prior to any subsequent transaction (read or write) on the record.
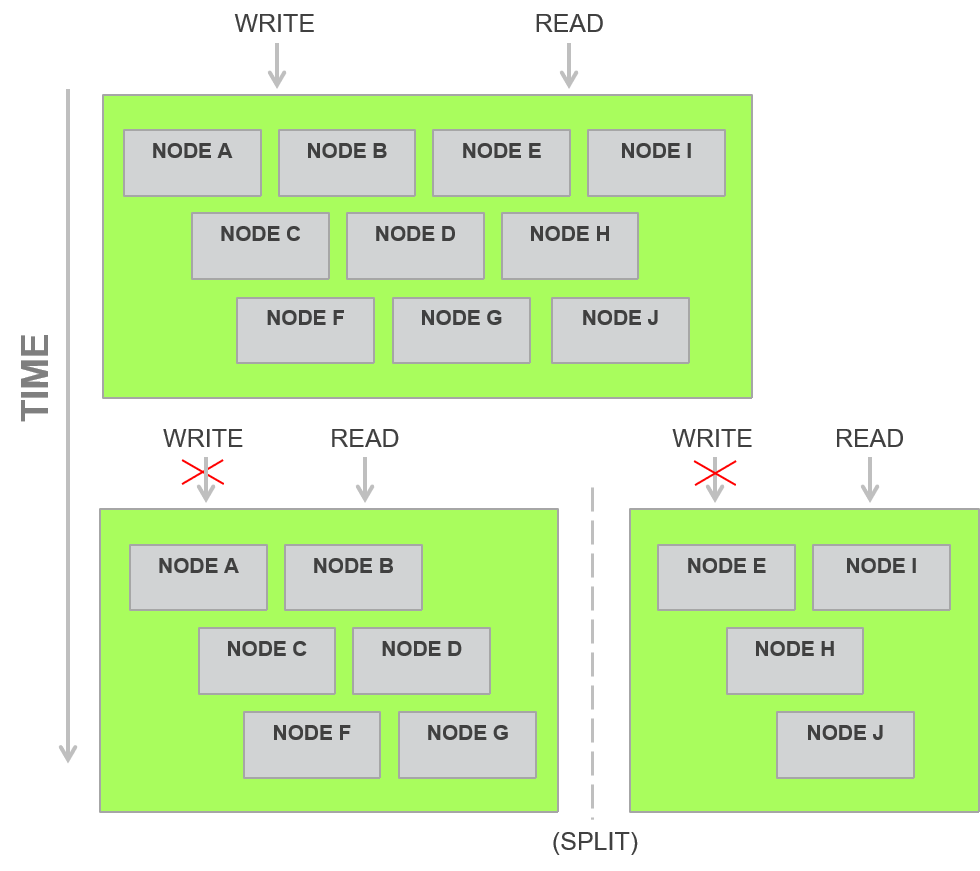
Figure 21: Split Brain cluster
Most systems for providing such strong consistency require a minimum of three copies to ensure that consistency properly, based on Lamport's proof that a consistency algorithm requires three copies of data. So, if a cluster splits as shown in Figure 21, one of the two sub parts can allow writes if it has a majority (two out of three) copies of the data item.
Aerospike optimizes this further by regularly allowing storing only two copies but using an adaptive scheme that adds more write copies on the fly in situations where they are necessary, thus optimizing the performance in the normal case while incurring a small amount of overhead in edge cases that rarely occur. In SC mode, Aerospike first defines a roster for the cluster.
Roster of nodes
This defines the list of nodes that are part of the cluster in steady state. When all the roster nodes are present and all the partitions are current, the cluster is in its steady state and provides optimal performance. As described in the partition algorithm earlier, the master and replica partitions are assigned to nodes in a cluster using a random assignment of partitions to nodes. In the case of SC, these partitions are referred to as roster-master and roster-replica. For the purpose of simplifying the discussion, we will restrict ourselves to a system with replication factor set to 2. Every partition in the system will have one master and one replica.
First some terminology:
roster-replica – For a specific partition, the roster-replica refers to the
node that would house the replica of this partition if all nodes in the roster
were part of the single cluster, i.e., the cluster was whole.
roster-master – For a specific partition, the roster-master refers to the
node that would house the master of this partition if all nodes in the roster
were part of the single cluster, i.e., the cluster was whole.
The following rules are now applied to the visibility of partitions:
- The cluster or sub-cluster must have enough nodes to accommodate the configured replication factor.
- If a sub-cluster (a.k.a. split-brain) has both the roster-master and roster-replica for a partition, then the partition is active for both reads and writes in that sub-cluster.
- If a sub-cluster has a majority of nodes and has either the roster-master or roster-replica for the partition within its component nodes, the partition is active for both reads and writes in that sub-cluster.
- If a sub-cluster has exactly half of the nodes in the full cluster (roster) and it has the roster-master within its component nodes, the partition is active for both reads and writes.
The above rules also imply the following:
100% availability on rolling upgrade: If a sub-cluster has fewer than replication factor number of nodes missing, then it is termed a super-majority sub-cluster and all partitions are active for reads/writes within the cluster.
100% availability on two-way split-brain: If the system splits into exactly two sub-clusters, then all partitions are active for reads and writes in one or the other sub-cluster (we will later show how to use this in a creative way for a rack-aware based HA architecture).
Consider as an example, partition p in a 5-node cluster where node 4 is the roster-replica for p and node 5 is the roster master for p. You can see below in Figure 22, Figure 23, Figure 24 and Figure 25 examples of when a partition is available or not in various partitioning situations.

Figure 22: All roster replicas are active, whole cluster

Figure 23: Minority sub-cluster has both roster-master and roster-replica, p is active

Figure 24: Roster-replica is in majority sub-cluster, becomes master, p is active, new replica in node 3

Figure 25: Roster-master and roster-replica are in minority clusters, p is inactive
Full partitions versus subsets
As you can see above, in steady state, partitions are considered full (in that they have all the relevant data). In some cases, for example in Figure 24 above where an alternate replica of the partition p was created in Node 3, the partition on node 3 is only a subset until all of the data in the partition copy on Node 4 is synchronized with Node 3. Node 4 has a full copy of partition p since it split off from a fully available cluster. There are rules on when and how to check for the second copy in order to ensure linearizability versus sequential consistency. We will illustrate this using the following scenario.
In a cluster with five nodes A, B, C, D, E, consider partition q that has Node A as roster-master, and Node B as roster-replica. Consider a rolling upgrade where one node is taken down at a time. Initially Nodes A and B start out as full partitions for q. When Node A is taken down, Node B which is roster-replica promotes to alternate master for q and Node C becomes alternate replica for q. Node C’s copy of partition q is now a subset. Soon enough Node A rejoins the cluster (as subset) after the successful software upgrade and the node B now goes down for its turn to be upgraded. At this point, there has not been enough time for the roster-master A to complete synchronization of all its data with B (that was Full). We are left with Node A as roster-master that is a subset for partition q and also node C that is another subset for q. At this point because this is a super cluster, we are guaranteed that among all the nodes in the cluster, all updates to the partition are available. This is because every update has to be written to at least two nodes (replication factor 2) and at most one node has been down at any one time. All changes must still be in one of these nodes. However, what this means is that for all reads to records that go to A (roster-master) every request has to resolve itself on a record-by-record basis with the partition subset stored in node C. This will temporarily create extra overhead for reads. Write overhead is never increased as Aerospike writes to both copies all the time.
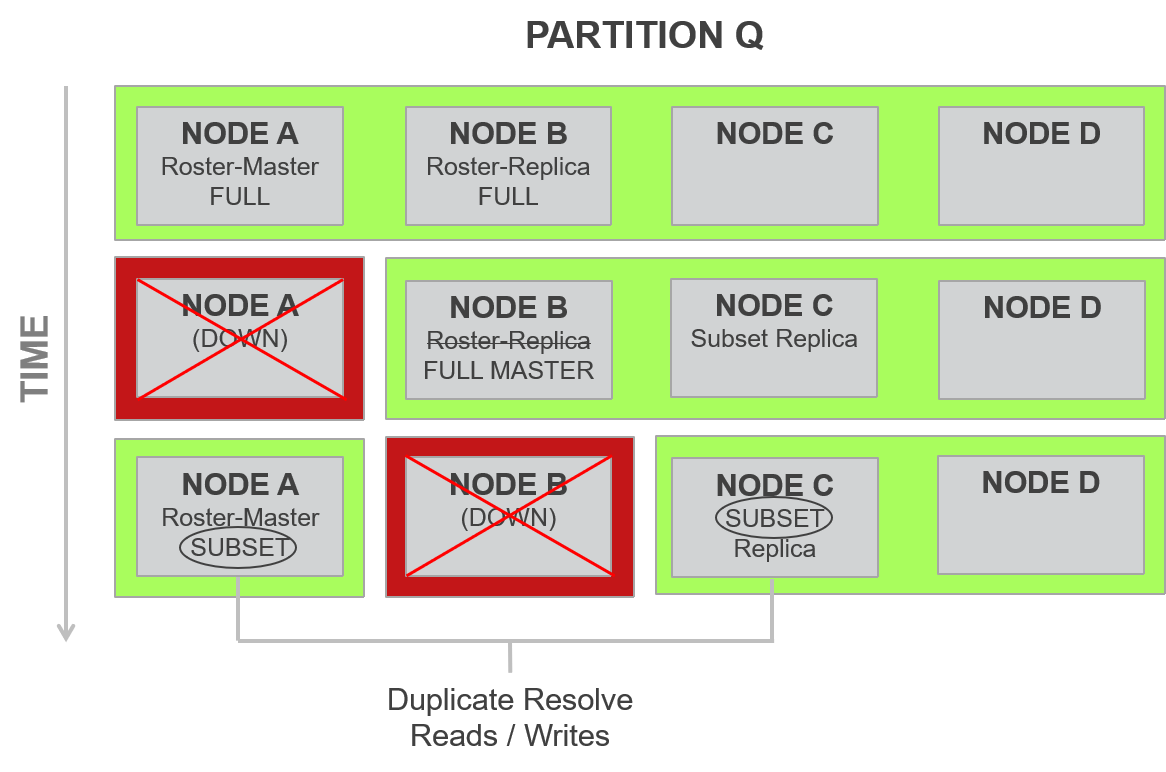
Figure 26: Subset and Full Partitions during rolling upgrade process So, the earlier rules are qualified further as follows:
- If a sub-cluster has all of the designated replicas (roster-master and roster-replicas) for a partition, and a full partition exists within the sub cluster then the partition is active for both reads and writes in that sub cluster
- If a sub-cluster has a majority of roster nodes and has either the roster-master or roster-replica for the partition within the component nodes and it has a full partition, then the partition is available
- If a sub-cluster has exactly half of the nodes in the full cluster (roster) and it has the roster-master within its component nodes, and it has a full copy of the partition, then the partition is active for both reads and writes
- If the sub-cluster has a super majority (i.e., fewer nodes than replication factor are missing from the sub-cluster), then a combination of subset partitions are sufficient to make the partition active.
There are some special kind of nodes that are excluded while counting the majority and super-majority:
- A node with one or more empty drives or a brand-new node that has no data
- A node that was not cleanly shutdown (unless commit-to-device) is enabled
Such nodes will have a special flag called “evade flag” set until they are properly inducted into the cluster with all of the data
While we discussed the above using replication factor 2, the algorithm extends to higher replication factors. All writes are written to every replica so the write overhead will increase as replication factors increases beyond 2.
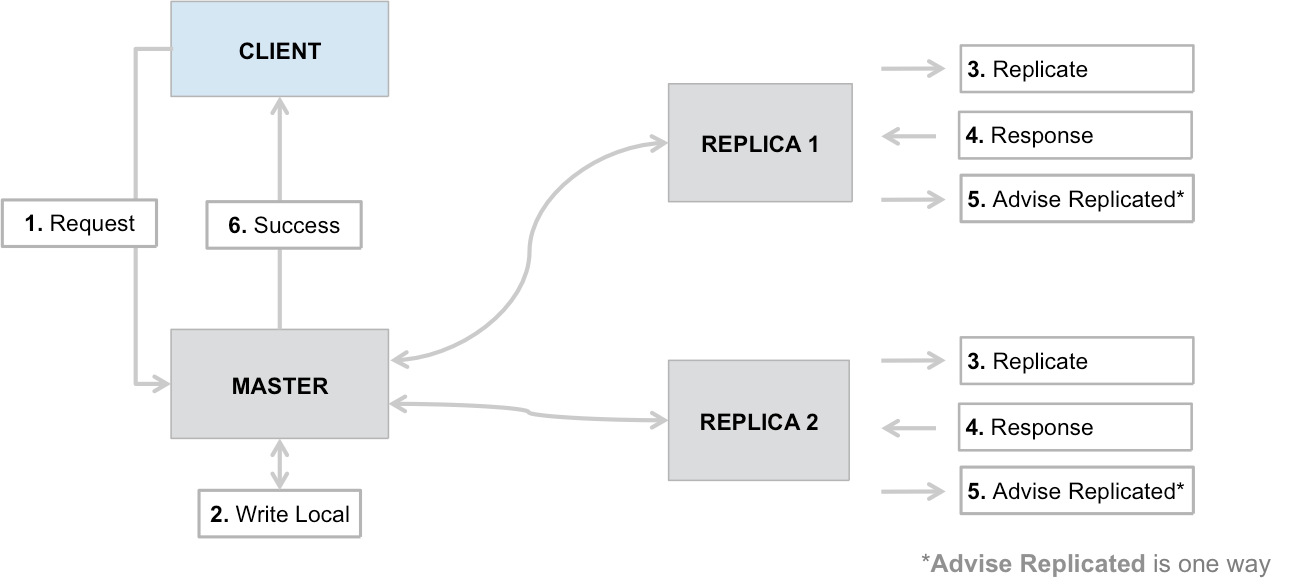
Figure 27: Write logic
The write logic is shown in Figure 27. All writes are committed to every replica before the system returns success to the client. In case one of the replica writes fails, the master will ensure that the write is completed to the appropriate number of replicas within the cluster (or sub-cluster in case the system has been compromised.)
SC for reads
In Aerospike SC mode, reads are always sent to the master partition. The main invariant that the client software depends on is that the server maintains the single master paradigm. However, Aerospike being a distributed system, it is possible to have a period when multiple nodes think they are master for a partition. For example, in the case where node A of a cluster is separated from the other four nodes B, C, D and E, B automatically takes over for partition q and C becomes a new replica.
It is important to differentiate the versions of the partitions where the writes are being done. The only successful writes are those made on replication-factor number of nodes. Every other write is unsuccessful. Also, it is only possible for exactly one sub-cluster to take over as master for a partition based on rules mentioned earlier. Even in this case, it is not possible to separate out the writes that happen in a master overhang period by using just timestamps alone. So, Aerospike added a concept of regime for a partition. This regime is incremented every time a master handoff for a partition happens. Only the old master uses the earlier regime and all writes to the new master will use the next regime. This means that changes made to a partition at a master node that has not yet processed the cluster change can be discarded by comparing to a greater regime number of the new sub-cluster where the data is active.
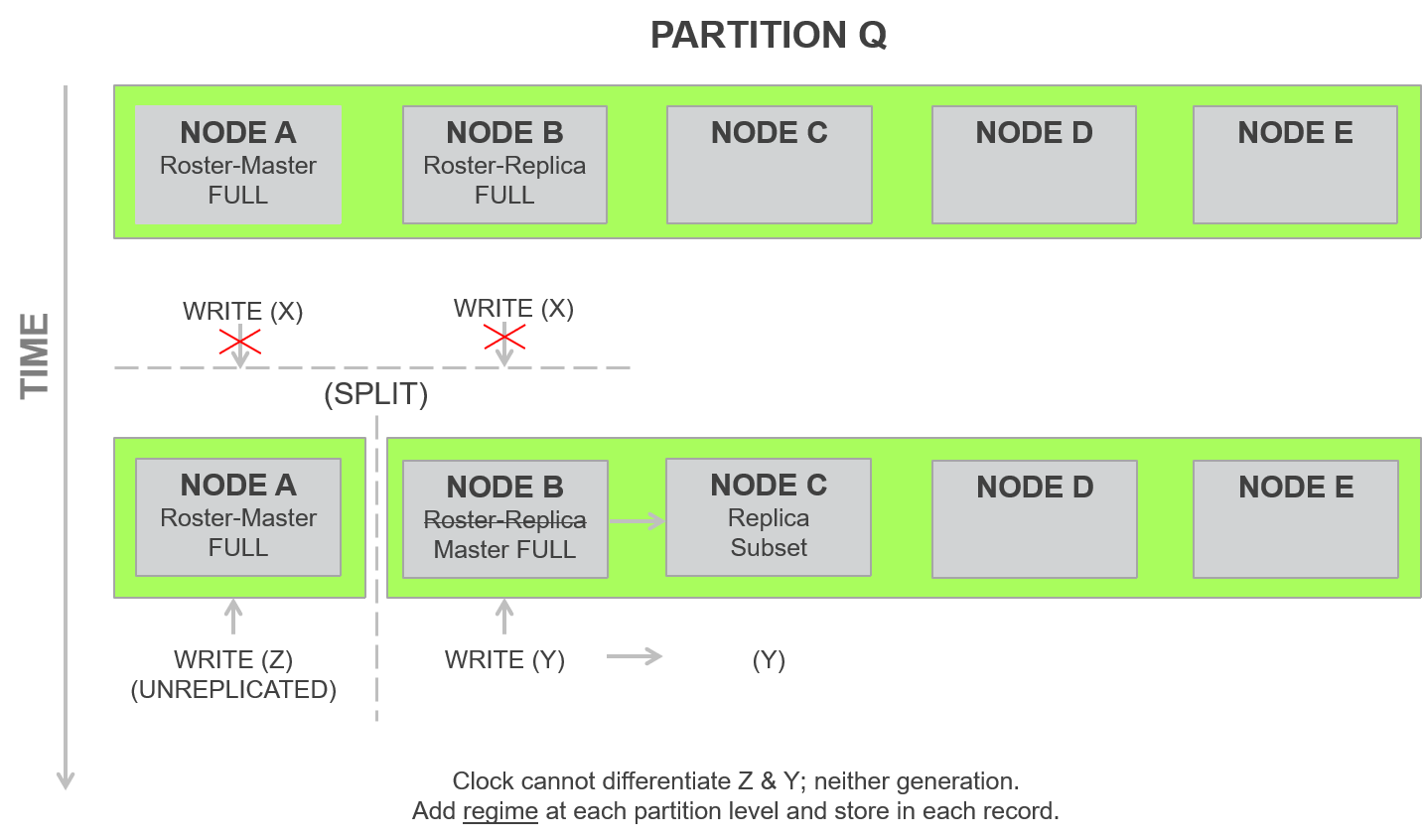
Figure 28: Clock that includes regime, last update time, and record generation
Aerospike uses the following per record as the mechanism to isolate the record updates:
- 40 bits of record last update time (LUT)
- 6 bits of partition regime
- 10 bits of record generation
The 6 bits of regime provides about 27 seconds of buffer based on 1.8 seconds for heartbeat intervals and accounts for around 32 cluster changes happening in the period. The combination of regime and LUT and generation provides an accurate path to determine which of the records in the system is the right value for reading and writing.
Linearizing reads
Based on the above, in order to linearize reads at the server, every read to the master partition needs to verify that the partition regimes are in sync for the partition in which the key is located. If the regimes agree then the read is guaranteed to be current. If the regimes do not agree this means that a cluster change may be in process and it is important to redo/retry the read from the client. Thus, for every write, all copies of the partition being written need to also have the same regime.
Session/Sequential Consistency
In this case, the read from the master is all that is needed on the server-side. The Aerospike client (library) stores the partition regime, a 32-bit partition version counter, as part of its partition table based on the latest regime value it has encountered for a partition on its read. This is to ensure that the Aerospike client (library) rejects any reads from servers of an older regime than the one it has already read. This could happen due to an especially large master overhang caused by slow system behavior or suspension/slowdown of virtual machines in cloud environments.
Relaxed Consistency
There are also two Relaxed Consistency client policies: 'allow replica' and 'allow unavailable'. With the Relaxed Consistency modes, the client will continue to read only committed records but reads will no longer be strictly monotonic.
In practice, it is very difficult to encounter scenarios where the 'allow replica' policy violates Session Consistency. This policy means applications using SC won't see read timeouts which may otherwise occur when a node (or rack) goes down. Additionally, it enables clients to make use of the 'preferred rack' policy which is often used to reduce cross-zone network utilization in various cloud environments.
The 'allow unavailable' policy relaxes consistency further by allowing clients to read previously committed records on partitions marked as unavailable. This mode allows applications which are sensitive to read unavailability to continue to function during a major network/cluster disruption. When partitions are available this policy behaves exactly like 'allow replica'.